Blog
A data science blog for Petroleum Engineering.Topics covered
artificial-intelligence
artificial-lift
batch-automation
business-case
cloud
computational-physics
computer-science
conference
courses
data-driven-vs-physics
data-engineering
data-science
data-scientists
data-structures
datasets
deep-learning
engineering-library
fluid-properties
gas-lift
geology
geophysics
geoscience
latex
linux
literate-programming
logs
loose-questions
machine-learning
modeling
open-source-software
paper-research
petroleum-engineering
petrophysics
production-technology
prosper
pvt
python
r
r-package
reproducibility
reservoir-engineering
reservoir-simulation
seismic
shiny
spe
statistics
text-mining
tikz
to-do
transcript
virtualization
visualization-of-data
vlp
volve
webapp
well
well-data
well-logs
well-modeling
Subject ▸ machine learning
Using application microprocessors for seismic
First practical application that I know of using the next thing after TPUs (Tensor Processing Units): ASICs or Application Specific Integrated Circuit. Ideal dedicated hardware for the massive seismic data and processing. Machine Learning (ML) algorithms build a mathematical model based upon representative sample data, known as ‘training data’, in order to make predictions or decisions without being explicitly programmed to perform the task. I limit my discussion here to supervised learning in the context of a potential application to seismic data image processing of a real marine seismic dataset, and then discuss how the computational scale of such exercises reinforce the need to develop computing technology that is customized for large ML problems.Any Petroleum Engineer can do reproducible Machine Learning
As I prepare to release couple of examples using Generative Adversarial Networks (GANs) for creating synthetic datasets using rTorch, I found that I have several Rmarkdown notebooks loose out there while learning PyTorch. So, I decided to put these notebooks in a sort of an online ebook in GitHub. These notebooks range from unit tests for testing functions I implemented in *rTorch*, a wrapper of PyTorch, written in R, to small neural networks for logistic regression and linear regression.A Generative Adversarial Networks (GAN) in rTorch for creating synthetic datasets. Season 1 Episode 1
Introduction I recently finished double-converting, from Python to R, and from PyTorch to rTorch, a very powerful script that creates synthetic datasets from real datasets. Synthetic datasets are based on real data but altered enough to keep the privacy, confidentiality or anonymity, of the original data. Since synthetic datasets conserve the original statistical characteristics of the real data, this could represent a breakthrough in petroleum engineering for sharing data, as the oil and gas industry is well known for the secrecy of its data.R and Python commingled: RPyStats in Windows and Linux. Season 1, Episode 6
Alright! We have two Rmarkdown notebooks written in Python and R running PyTorch libraries. There are many more things that still we can do to improve the accuracy of the model to recognize hand-written digits. But before we continue improving the algorithm and the model, I wanted to make a brief pause and showed you something that really made me jump ship from Windows to Linux. It is related to R, Python and data science.R and Python commingled: Creating a PyTorch project with RPyStats. Season 1, Episode 5
In the previous episode we ended up calculating the accuracies for the MNIST digits model using PyTorch libraries called from a Rmarkdown notebook written in Python. In this episode, we will run the same example but in another notebook written in R named *mnist_digits_rstats.Rmd*, which was saved in the folder ./work/notebooks in the previous session. With RStudio open, let’s click on the file to open it. You may notice some familiarity between the code in this notebook *mnist_digits_rstats.R and Python commingled: Creating a PyTorch project with RPyStats. Season 1, Episode 4
Introduction Now that you have your machine with the core applications installed (Season1, Episode 3), in this episode we will cover the steps to create a machine learning project commingling R and Python. I will call this project rpystats-apollo11. What rpystats-apollo11 will do is training a neural network using the MNIST dataset to recognize hand-written digits. I will write the code in pure Python first, and then in R in two separate Rmarkdown notebooks running in RStudio.Hinton's Coursera course *Neural Networks for Machine Learning*
The machine learning course is little heavy in math but I would recommend to, at least, taking a look at some of the lectures to find out what AI and ML are about. You can browse as much as you want, for free, in Coursera.
Machine Learning for lithofacies classification from well logs by Paolo Dell'Aversana
Don’t miss reading this paper on an application of machine learning in petroleum engineering by Paolo Dell’Aversana.
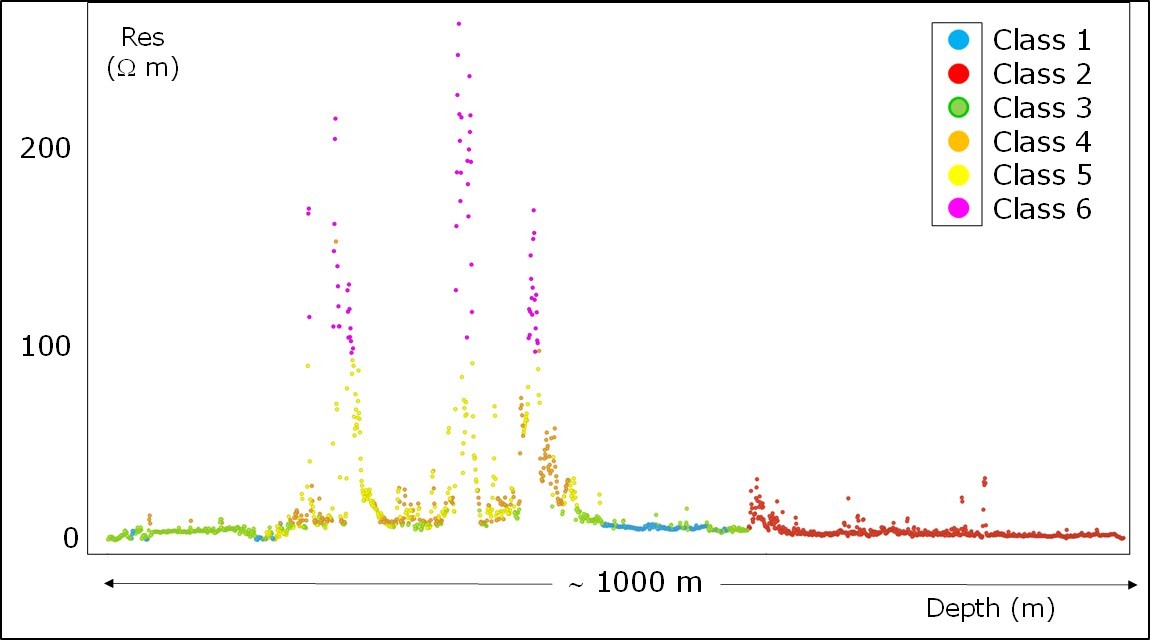
References
Reinforcement Learning. Not an easy subject
Not an easy subject nor as common as supervised and unsupervised learning but key for making better intelligent machines.
Book by Andrew Barto and Richard S. Sutton: https://lnkd.in/ewb_MeJ
#petroleumengineering #machinelearning #digitalpetroleum #datascience