Blog
A data science blog for Petroleum Engineering.Topics covered
artificial-intelligence
artificial-lift
batch-automation
business-case
cloud
computational-physics
computer-science
conference
courses
data-driven-vs-physics
data-engineering
data-science
data-scientists
data-structures
datasets
deep-learning
engineering-library
fluid-properties
gas-lift
geology
geophysics
geoscience
latex
linux
literate-programming
logs
loose-questions
machine-learning
modeling
open-source-software
paper-research
petroleum-engineering
petrophysics
production-technology
prosper
pvt
python
r
r-package
reproducibility
reservoir-engineering
reservoir-simulation
seismic
shiny
spe
statistics
text-mining
tikz
to-do
transcript
virtualization
visualization-of-data
vlp
volve
webapp
well
well-data
well-logs
well-modeling
Subject ▸ datasets
Reading wells from SPE data repository
Okay. There are two ways of downloading the data for all the wells in the SPE repository: the manual way (one file at a time with “Save As”), and the non-interactive automated way. The manual way is the easiest and require that you provide your SPE username and password in your usual login page. Then, you click on the link to the repository https://www.spe.org/datasets/, and start right-clicking on each of the files under the data folders.Reservoir Simulation Datasets
README Purpose of these datasets is using them for testing using MRST and its derivative Proof of Concept (POC) in Pyhon using the machine learning library PyTorch. Since PyTorch has built-in functionality to work with Graphics Processing Units or GPUs, we expect demonstrating -before embarking in the full porting of MRST-, that PyTorch GPU-based tensors could significantly reduce compute time during reservoir simulation. Evaluation for Proof of Concept The steps are the following:A Generative Adversarial Networks (GAN) in rTorch for creating synthetic datasets. Season 1 Episode 1
Introduction I recently finished double-converting, from Python to R, and from PyTorch to rTorch, a very powerful script that creates synthetic datasets from real datasets. Synthetic datasets are based on real data but altered enough to keep the privacy, confidentiality or anonymity, of the original data. Since synthetic datasets conserve the original statistical characteristics of the real data, this could represent a breakthrough in petroleum engineering for sharing data, as the oil and gas industry is well known for the secrecy of its data.When Petrophysics Meets 'Data Science': What can Machines Do?
That is not the exact name of the paper. It actually is “When Petrophysics Meets Big Data: What can Machine Do?”, that was published recently in OnePetro. Link here. It’s a very good paper. A must read. Applicable to all disciplines in petroleum engineering. But, is there really “Big Data”? My only observation is how the authors struggle to explain data analysis in the context of “big data”. Big data is a misnomer and really doesn’t mean anything in science, or data science, for that matter.The impact of the Volve dataset
This is a part of the response I wrote to a reader in my [blog](http://blog.oilgainsanalytics.com/blog/. The question was about the limited scope of the Volve license, questioning its openness, because it doesn’t cover commercialization from the data. This was my response: I am not finding any problem whatsoever. For my purposes of research, learning, education and teaching, I think the license is alright. In all articles and papers I always give the corresponding attribution.Seismic report 1.2 TB
Volve dataset.
Seismic report from the 1.2 terabytes file.
[ ](/files/ST0202 Volve 4C FFOR.pdf)
](/files/ST0202 Volve 4C FFOR.pdf)
Seismic report 2.6 TB
Volve dataset. Seismic report from the 2.6 terabytes file.
I was able to selectively download the report for the seismic acquisition in file Volve_Seismic_ST10010.zip. Thanks Yogendra Narayan Pandey for the Azure Explorer tip.
Does anyone with seismic expertise notice information of relevance?

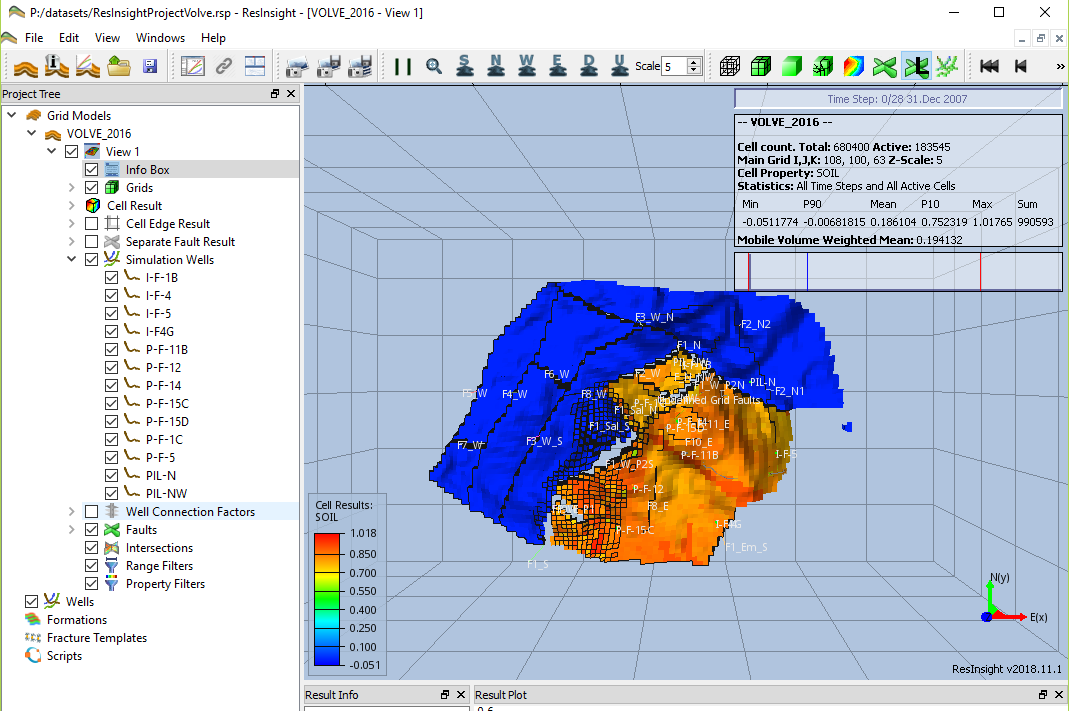
Volve dataset. First look of the Reservoir simulation models.
The Eclipse reservoir models from the Volve dataset working like a charm. The compressed file is 399 MB in size.
I was able to open the models with ResInsight (thank you Matthew Kirkman). The software is open source and relatively easy to use.
Here is the Eclipse case opened.
1`