Blog
A data science blog for Petroleum Engineering.Topics covered
artificial-intelligence
artificial-lift
batch-automation
business-case
cloud
computational-physics
computer-science
conference
courses
data-driven-vs-physics
data-engineering
data-science
data-scientists
data-structures
datasets
deep-learning
engineering-library
fluid-properties
gas-lift
geology
geophysics
geoscience
latex
linux
literate-programming
logs
loose-questions
machine-learning
modeling
open-source-software
paper-research
petroleum-engineering
petrophysics
production-technology
prosper
pvt
python
r
r-package
reproducibility
reservoir-engineering
reservoir-simulation
seismic
shiny
spe
statistics
text-mining
tikz
to-do
transcript
virtualization
visualization-of-data
vlp
volve
webapp
well
well-data
well-logs
well-modeling
Subject ▸ Volve
A simple Binder project with a Volve dataset
Test binder with simple Volve project. Using the project set up by Navarro on well logs.
Build with R and Jupyter.
A Vagrant virtual machine to run data science on Volve datasets
vagrant-volve-navarro-BI64G20S2JP8201 This is reproducible work of Machine Learning and Data Science applied to data from the Volve field. Features This is a VirtualBox Virtual Machine (VM) that is automatically generated using Vagrant. A few Machine Learning and Deep Learning packages have been installed, such as Scikit-Learn, NLTK, Keras, TensorFlow and Theano. A Vagrant file is used to generate this VM based on Ubuntu 18.04 (bionic64). Additional packages required for this phase of the ML and DS work are welly, pandas, numpy, seaborn, and lasio.The impact of the Volve dataset
This is a part of the response I wrote to a reader in my [blog](http://blog.oilgainsanalytics.com/blog/. The question was about the limited scope of the Volve license, questioning its openness, because it doesn’t cover commercialization from the data. This was my response: I am not finding any problem whatsoever. For my purposes of research, learning, education and teaching, I think the license is alright. In all articles and papers I always give the corresponding attribution.Integrating Python and R for data science. Converting Eclipse binary files to dataframes in the Volve dataset
Introduction Python and R offer a good combination of powers: dozens of proven engineering, data science, and machine learning libraries, also a science oriented approach towards full reproducibility. As I have told you before, I started my coding journey with Python many years ago. I even wrote a large application for production optimization using OpenServer, Prosper, GAP and MBAL by Petroleum Experts while I was on my 3-year tour with Petronas in Kuala Lumpur in Malaysia.Volve dataset. First look of the Reservoir simulation models.
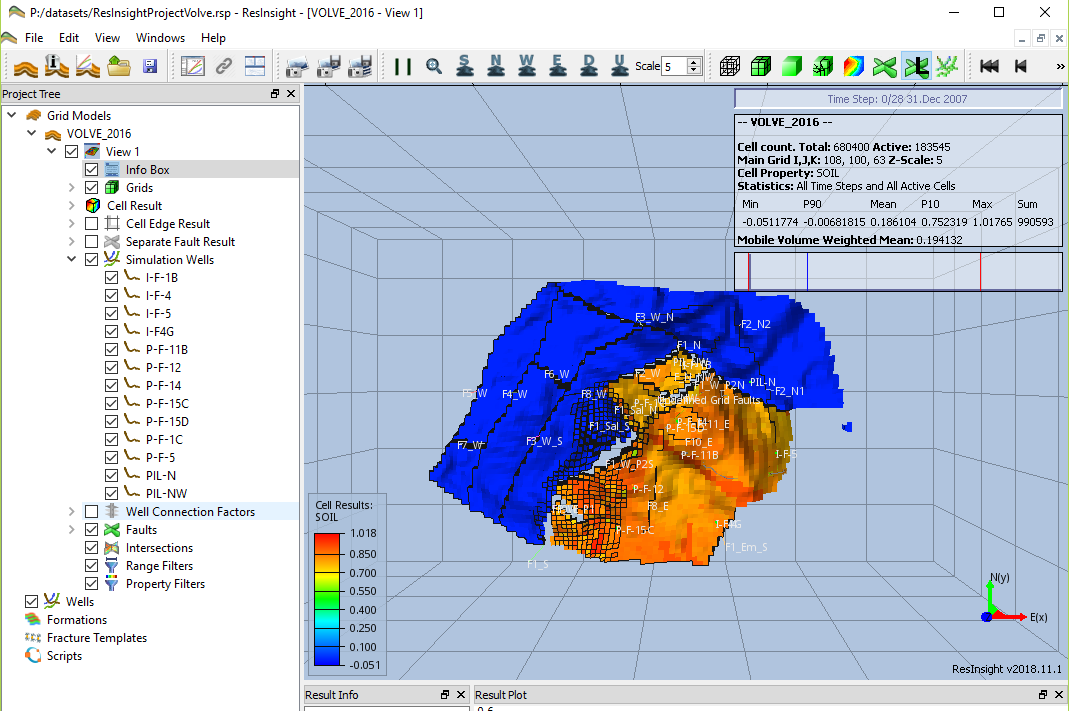
The Eclipse reservoir models from the Volve dataset working like a charm. The compressed file is 399 MB in size.
I was able to open the models with ResInsight (thank you Matthew Kirkman). The software is open source and relatively easy to use.
Here is the Eclipse case opened.
1`