Motivation
I have been lately curious about how the terms data science, machine learning and artificial intelligence evolved over the years in petroleum engineering papers. It is not that machine learning or data science are brand new fields of study; quite the contrary, they have been around for decades, as it has been artificial intelligence.
Procedure
The current hype is due to (i) the sheer computational power available; (ii) the availability of fast engines in the cloud; (iii) open source software such as Python, R, Octave, Hadoop, Spark, Scala, MongoDB, Javascript, VirtualBox, containerization tools; (iv) an operating system that runs under all platforms Unix/Linux and different microprocessor architectures;; (v) the almost-free online education by some of the best professors in the world; (vi) and the dissemination of knowledge through the internet (books, papers, articles). It all have commingled at the right time, at the right places (everywhere).
Initially, I will do the search using the R package petro.One - that I have updated few days ago (thanks, William “Bill” Donovan for your inquiries)-, while on a quest for finding the right papers given few keywords on the subject.
I will not give an opinion on what the trends mean for the moment. Let’s see the numbers to sink in for couple of days. Besides, I might not have come with all the right keywords for this quick study.
Can you think of keywords relevant to the matter in discussion?
I will start with the broad terms of the moment: artificial intelligence, machine learning and data science. From there, we could try some combinations, precursors and derivatives of the terms, and we’ll see what is the trend.
The number of papers is on y-axis, the year on the x-axis. I am using a Rmarkdown notebook for this article; R version 3.5.2 and RStudio 1.2.1226. To get the data, I am interrogating the OnePetro website. The R package I wrote, petro.One, simplifies the search by extracting the papers in multiples of one thousand (the maximum allowed by OnePetro), and creates the corresponding datasets in the shape of tables. You can take a look at the petro.One website here.
Artificial Intelligence
First, what year do you see mentions of the keyword -the whole term “artificial intelligence” (we are not looking for separate words), or starts being used in petroleum engineering papers?
When do we see a fast increment on papers with mentions of
artificial intelligence?Do we see a peak?
Is the trend ascendant or descendant?
# artificial intelligence
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("artificial intelligence")
results_ai <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_ai <- results_ai$papers)
#> Error in eval(expr, envir, enclos): object 'results_ai' not found
# plot on AI by year of publication
papers_ai %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_ai_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "'Artificial Intelligence' papers by Year")
#> Error in group_by(., year): object 'papers_ai' not foundComputational Intelligence
Computational Intelligence is another term that have seen frequently used by scholars instead of artificial intelligence. Some of them think that there is no artificial intelligence but that originated from computers. Makes sense. Unless we are talking of biological duplication of human intelligence. You will see the term computational intelligence in books and papers outside petroleum engineering.
# computational intelligence
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("computational intelligence")
results_ci <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_ci <- results_ci$papers)
#> Error in eval(expr, envir, enclos): object 'results_ci' not found
# plot on CI by year of publication
papers_ci %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_ci_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Computational Intelligence papers by Year")
#> Error in group_by(., year): object 'papers_ci' not foundIntelligence
We humans have been very passionate about bringing about certains forms of intelligence. From ancient times we were just looking to replace humans in certain repetitive tasks. We could safely says that the endeavor is 3000 years old. Plato and Aristoteles are mentioned in literature on the origins of AI, but really goes further back in time if we investigate other civilizations.
# intelligence
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("intelligence", "intelligent")
results_ii <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_ii <- results_ii$papers)
#> Error in eval(expr, envir, enclos): object 'results_ii' not found
# plot on II by year of publication
papers_ii %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_ii_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "On `Intelligence` papers by Year")
#> Error in group_by(., year): object 'papers_ii' not foundMachine Learning
Machine Learning is a term of more recent origin. We can tell just by looking at linearregression` as one of the most used or common machine learning algorithm, notwithstanding that liner regression has been around hundreds of years.
So the joke goes:
if you can run a linear regression then you are doing machine learning. Therefore, you are in the artificial intelligence business.
:) You know that something is not right!
# machine learning
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("machine learning")
results_ml <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_ml <- results_ml$papers)
#> Error in eval(expr, envir, enclos): object 'results_ml' not found
# plot on ML by year of publication
papers_ml %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_ml_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on 'Machine Learning' by Year")
#> Error in group_by(., year): object 'papers_ml' not foundAlgorithm
This is another keyword of common use these days. Machine Learning is about algorithms.
# algorithm
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("algorithm")
results_algo <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_algo <- results_algo$papers)
#> Error in eval(expr, envir, enclos): object 'results_algo' not found
# plot on algos by year of publication
papers_algo %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_algo_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers using the term 'Algorithm' by Year")
#> Error in group_by(., year): object 'papers_algo' not found# predictive analytics
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("predictive analytics")
results_pa <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_pa <- results_pa$papers)
#> Error in eval(expr, envir, enclos): object 'results_pa' not found
# plot on algos by year of publication
papers_pa %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_pa_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers using the term 'Predictive Analytics' by Year")
#> Error in group_by(., year): object 'papers_pa' not found# statistical model
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("statistical model")
results_sm <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_sm <- results_sm$papers)
#> Error in eval(expr, envir, enclos): object 'results_sm' not found
# plot on algos by year of publication
papers_sm %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_sm_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers using the term 'Predictive Analytics' by Year")
#> Error in group_by(., year): object 'papers_sm' not foundData Science
This is where the fun starts. No machine learning or artificial intelligence effort is possible without the application of data science. No dataset, no ML. No ML algorithm, no AI. Pretty simple.
# data science
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("data science")
results_ds <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = FALSE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = FALSE, : could not find function "run_papers_search"
(papers_ds <- results_ds$papers)
#> Error in eval(expr, envir, enclos): object 'results_ds' not found
# plot on DS by year of publication
papers_ds %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_ds_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on Data Science by Year")
#> Error in group_by(., year): object 'papers_ds' not foundPrecursors, derivatives of “data science”
Data Science is a relatively new term; there are other that have been widely used in SPE papers, such “data driven”, “data-driven”, “data-driven analytics”, “data analysis”, etc.
The data-driven terms has been profusely present in petroleum engineering papers.
# data driven
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("data driven", "data-driven")
results_dd <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = TRUE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = TRUE, len_keywords = 4, : could not find function "run_papers_search"
(papers_dd <- results_dd$papers)
#> Error in eval(expr, envir, enclos): object 'results_dd' not found
# plot on DD by year of publication
papers_dd %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_dd_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on Data Driven by Year")
#> Error in group_by(., year): object 'papers_dd' not foundAnalytics
Analytics is one of the preffered terms in the media, press, and also in some paper studies. Sounds kind of nice and “sciency”.
# analytics
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("analytics")
results_an <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = TRUE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = TRUE, len_keywords = 4, : could not find function "run_papers_search"
(papers_an <- results_an$papers)
#> Error in eval(expr, envir, enclos): object 'results_an' not found
# plot on 'analytics' by year of publication
papers_an %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_an_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on 'Analytics' by Year")
#> Error in group_by(., year): object 'papers_an' not foundData Analytics
Data Analytics is another term that is used as an equivalent of data science. They may not have the same meaning for different authors or companies, but let’s assume for the moment they are practically the same. Personally, I think they are not. You don’t say, for instance, I am going to study “data analytics”. Do you?
# data analytics
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("data analytics")
results_da <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = TRUE, # show progress
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = TRUE, len_keywords = 4, : could not find function "run_papers_search"
(papers_da <- results_da$papers)
#> Error in eval(expr, envir, enclos): object 'results_da' not found
# plot on DA by year of publication
papers_da %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_da_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on 'Data Analytics' by Year")
#> Error in group_by(., year): object 'papers_da' not foundDiscussion
There you go. Some data and some plots to start the discussion.
As in data science, is all addressing questions. A business question.
What do you notice about the evolution of the terminology? How recent are they? Which is the oldest term? How far can you go back in time and say ‘it started here’? Where do you notice a most accentuated growing slope? Why data science is younger than data-driven? Do you think the authors were using the data-driven term to mean the future data science? Do you think data-driven analytics, data science, or just simply, analytics, are all the same?
And what about Big Data?
# big data
library(petro.One)
#> Error in library(petro.One): there is no package called 'petro.One'
library(dplyr)
library(ggplot2)
# provide two different set of keywords to combine as vectors
major <- c("big data")
results_bd <- run_papers_search(major,
get_papers = TRUE, # return with papers
verbose = TRUE, # show progress
sleep = 5, # wait time for OnePetro
len_keywords = 4, # naming the data file
allow_duplicates = FALSE) # by paper title and id
#> Error in run_papers_search(major, get_papers = TRUE, verbose = TRUE, sleep = 5, : could not find function "run_papers_search"
(papers_bd <- results_bd$papers)
#> Error in eval(expr, envir, enclos): object 'results_bd' not found
# plot on BD by year of publication
papers_bd %>%
group_by(year) %>%
na.omit() %>%
summarize(n = n()) %>%
{. ->> papers_bd_by} %>%
ggplot(., aes(x = year, y = n)) +
geom_point() +
geom_smooth(method = "loess") +
labs(title = "Papers on 'Big Data' by Year")
#> Error in group_by(., year): object 'papers_bd' not foundFinally, do you think the term big data is equivalent to data science, or data analytics? How do you think the term big data was originated?
Summary of all keywords
Artificial Intelligence by Year
# artificial intelligence
papers_ai_by$keyword <- "artificial intelligence"
#> Error in papers_ai_by$keyword <- "artificial intelligence": object 'papers_ai_by' not found
papers_ci_by$keyword <- "computational intelligence"
#> Error in papers_ci_by$keyword <- "computational intelligence": object 'papers_ci_by' not found
papers_ii_by$keyword <- "intelligence"
#> Error in papers_ii_by$keyword <- "intelligence": object 'papers_ii_by' not found
all_papers_ai <- rbind(papers_ai_by, papers_ci_by, papers_ii_by)
#> Error in rbind(papers_ai_by, papers_ci_by, papers_ii_by): object 'papers_ai_by' not found
all_papers_ai
#> Error in eval(expr, envir, enclos): object 'all_papers_ai' not found
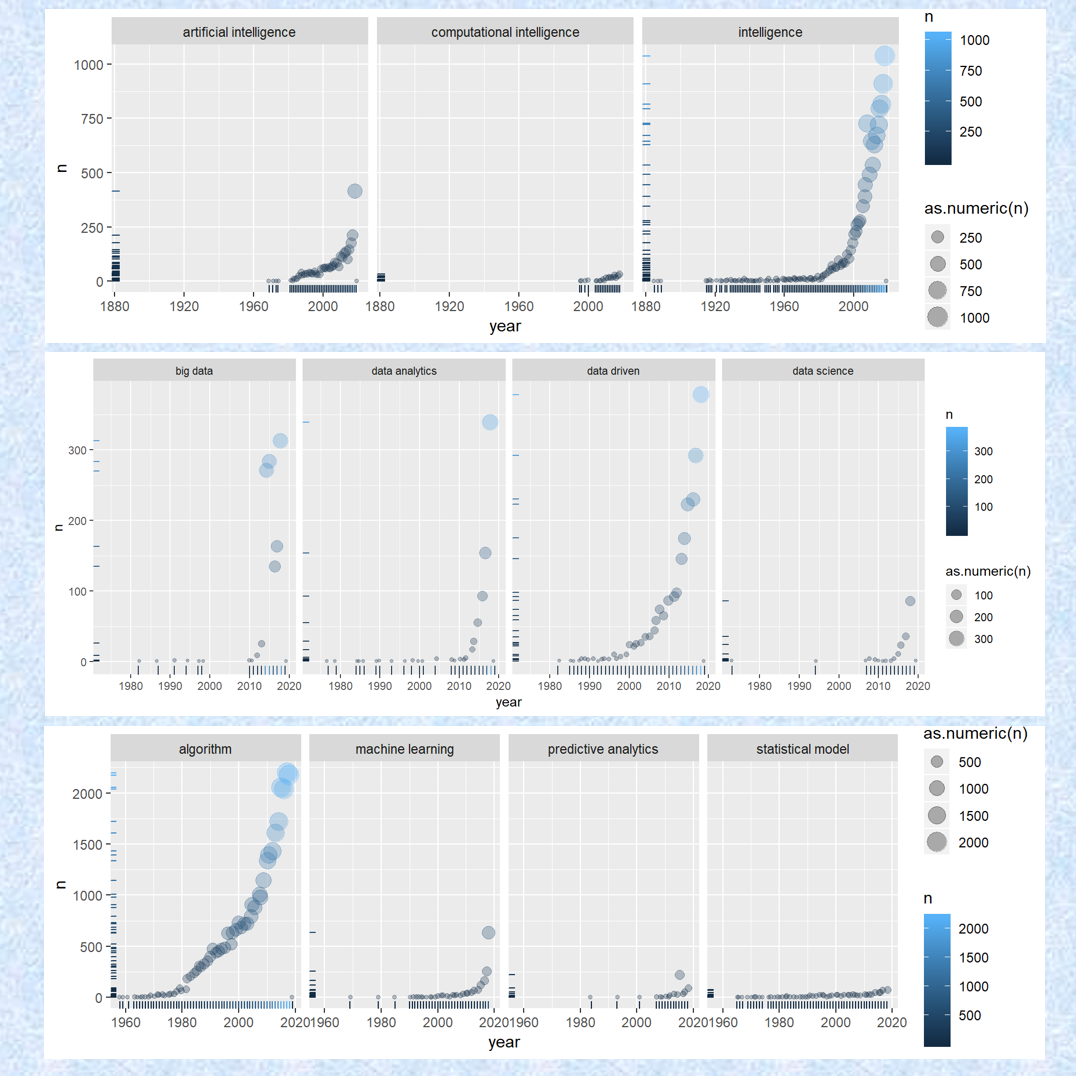
ggplot(data = all_papers_ai, aes(x = year, y = n, color = n)) +
geom_jitter(aes(size = as.numeric(n)), alpha = 0.3) +
geom_rug() +
facet_grid(. ~ keyword)
#> Error in ggplot(data = all_papers_ai, aes(x = year, y = n, color = n)): object 'all_papers_ai' not foundMachine Learning papers
# machine learning
papers_ml_by$keyword <- "machine learning"
#> Error in papers_ml_by$keyword <- "machine learning": object 'papers_ml_by' not found
papers_algo_by$keyword <- "algorithm"
#> Error in papers_algo_by$keyword <- "algorithm": object 'papers_algo_by' not found
papers_pa_by$keyword <- "predictive analytics"
#> Error in papers_pa_by$keyword <- "predictive analytics": object 'papers_pa_by' not found
papers_sm_by$keyword <- "statistical model"
#> Error in papers_sm_by$keyword <- "statistical model": object 'papers_sm_by' not found
all_papers_ml <- rbind(papers_ml_by, papers_algo_by, papers_pa_by, papers_sm_by)
#> Error in rbind(papers_ml_by, papers_algo_by, papers_pa_by, papers_sm_by): object 'papers_ml_by' not found
ggplot(data = all_papers_ml, aes(x = year, y = n, color = n)) +
geom_jitter(aes(size = as.numeric(n)), alpha = 0.3) +
geom_rug() +
facet_grid(. ~ keyword)
#> Error in ggplot(data = all_papers_ml, aes(x = year, y = n, color = n)): object 'all_papers_ml' not foundData Science papers
# data science
papers_ds_by$keyword <- "data science"
#> Error in papers_ds_by$keyword <- "data science": object 'papers_ds_by' not found
papers_da_by$keyword <- "data analytics"
#> Error in papers_da_by$keyword <- "data analytics": object 'papers_da_by' not found
papers_dd_by$keyword <- "data driven"
#> Error in papers_dd_by$keyword <- "data driven": object 'papers_dd_by' not found
papers_bd_by$keyword <- "big data" # NOTE. big data has been updated
#> Error in papers_bd_by$keyword <- "big data": object 'papers_bd_by' not found
all_papers_ds <- rbind(papers_ds_by, papers_da_by, papers_dd_by, papers_bd_by)
#> Error in rbind(papers_ds_by, papers_da_by, papers_dd_by, papers_bd_by): object 'papers_ds_by' not found
ggplot(data = all_papers_ds, aes(x = year, y = n, color = n)) +
geom_jitter(aes(size = as.numeric(n)), alpha = 0.3) +
geom_rug() +
facet_grid(. ~ keyword)
#> Error in ggplot(data = all_papers_ds, aes(x = year, y = n, color = n)): object 'all_papers_ds' not found