Introduction
This time we will be exploring drilling data that is stored using the industry standard WITSML. This format is widely used in the industry in drilling, completion and intervention operations, specifically for real-time surveillance. WITSML stands for Wellsite Information Transfer Standard Markup Language. It has a series of rules to save the data as a consistent schema but essentially is XML. Software developers and IT professionals in the oil industry know it very well. They mostly use in-house developed scripts, SDK1 in Java, [.Net]2, [C#]3, or applications provided by vendors. This standard is essential to send and receive data between the rig and the offices or servers.
Since we are not writing for software developers or IT techs but for petroleum engineers, we need to know at least the basics of WITSML. We don’t need to be experts on the subject but at least get familiar with the shape of the data, manipulation, perform some data exploration, and ultimately, be prepared, or know, what they are talking about when it is time to build an artificial intelligence agent based on a machine learning algorithm.
On Artificial Intelligence. Again, let’s touch Earth here. There is no robot, or Skynet Terminator, or an intelligent, cognitive entity in AI. Artificial Intelligence, or AI, is about making agents or applications to perform a repetitive or boring tasks that otherwise would be peformed by a human being. It is simple math, statistics and computer science.
Motivation
I have always been intrigued by WITSML. Not being a drilling engineer kepts me some distance away from the daily touch with this type of data. When I had the chance, I have explored the WITSML data with a XML viewer and one thing is clear: this is not your regular nice, rectangular data, or table, that we work every day. WITSML uses a hierarchical data structure, pretty similar to a tree: branches and leaves. This makes it very unusual to those who are familiar with just row and columns tables. What we will try to do in this lecture is getting a basic understanding of a different data structure. As a matter of fact, I find hierarchical data structures very applicable to production and reservoir engineering because they give us a lot of freedom in creating multiple levels for our data.
WITSML and the Volve Drilling Dataset
We were very fortunate of getting the Volve dataset published 7 months ago by Equinor. It covers a wide array of data from different disciplines (production, reservoir, geophysics, drilling, completion, logging, etc.), with data coming in different formats. It is a very good exercise of data science for exploring the data and making discoveries.
Here is a view of all the wells that are storing data in WITSML format:
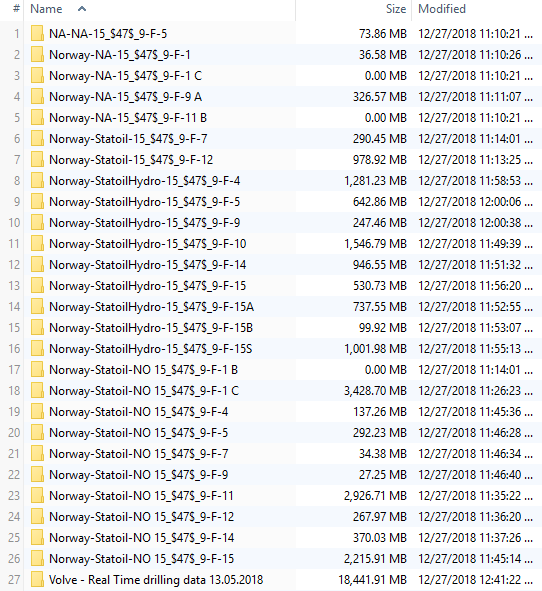
Look at the size of each folder. They are considerable large if we compare them to the usual files we manage every day. I am choosing the folder in row 22 (well 9f9), one of the smaller data containers (27.3 MB). If the data operations we perform here are all correct, then, the solution generalized, should apply well to any of the larger WITSML datasets.
A typical well with data stored in WITSML would look like this:
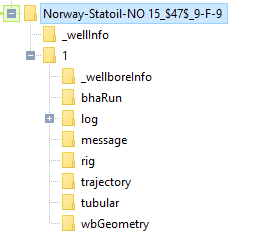
From all these folders, let’s focus today in the well trajectory dataset.
I downloaded all the drilling data for Volve which is about 26.8 GB. It’s not that big if we compare it to the seismic files of 1.2 and 2.4 terabytes. I chose the trajectory folder for well Norway-Statoil-NO 15_$47$_9-F-9 because it seemed complex enough to studying it. Besides, it wasn’t too big: around 27 MB. After learning from it, we could apply our data conversion algorithms to simpler datasets.
The trajectory folder and files
The trajectory folder is very simple. It contains WITSML files and a metadata information file (not important at this time). The folder could contain more than one file. We will see in another lecture wells with more than one trajectory file. In our example, the WITSML file has the name of 1.xml. We will be reading it in few seconds.
Parts of the trajectory dataset
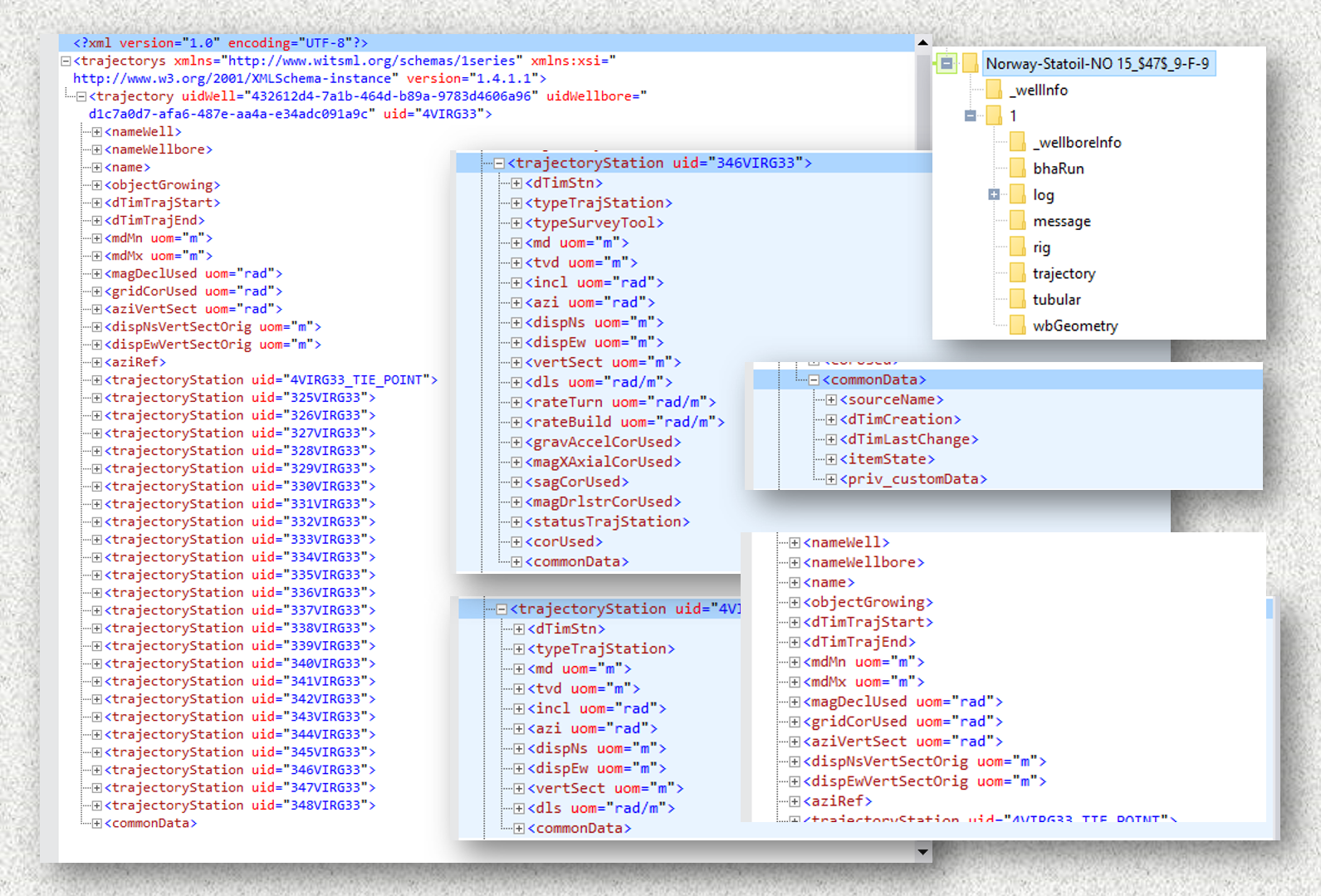
Let’s take a look first at the trajectory WITSML file. We are starting with a collapsed tree so it doesn’t take too much space of the screen. The (+) sign on the left means that it will expand further at that node if you click on it.
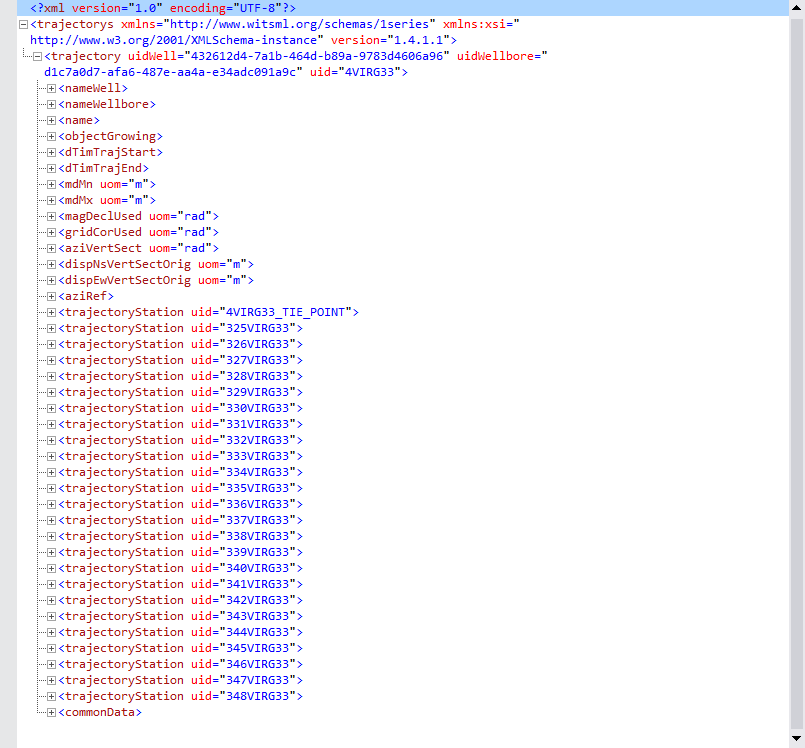
Note. I am using the software MindFusion XML Viewer to explore the WITSML files. I find it unobtrusive and simple to use. But any other viewer should be ok.
The two major nodes
Starting by the top, in the second line, see the first node: trajectorys. This is the root node. If you see one (-) sign on its left, it means it has been expanded. Following on the right, in red, you see labels such as xmlns, xlmns:xsi, and version. These are attributes of trajectorys. They are not nodes but attributes.
Under the root node trajectorys, you see that it has only one child called trajectory. If you see that is has a (-) sign, then it has been expanded showing all its dependent nodes.
So, there are then two major nodes: trajectorys and trajectory. Everything else exists under trajectory.
Secondary nodes
There is a group of nodes that coexists at the same level of the most important node which is trajectoryStation. This group of nodes is what we call siblings of trajectoryStation. These nodes are:
nameWell
nameWellBore
name
objectGrowing
dTimTrajStart
dTimTrajEnd
mdMn
mdMx
gridCorUsed
aziVertSect
dispNsVertSectOrig
dispEwVertSectOrig
aziRef
...
...
...
commonDataThe three dots correspond to trajectoryStation items.

Some of these nodes will have children, others will just contain values as is the case of the nodes that go from nameWell up to aziRef.
Some of these nodes are standalone and other have dependent nodes or children. We will see later how we find that out without having to expand each of the nodes.
The node commonData, for instance, is one that has children. That node will require special treatment to retrieve its data.
The measurement nodes
The nodes trajectoryStation are the most important nodes in the whole dataset. They actually using very well this hierarchical data structure to keep track of the trajectory of the well. Each of the nodes for trajectoryStation carries a unique measurement and a unique identifier called uid.
The node trajectoryStation has also child nodes as we show below for the first child member.
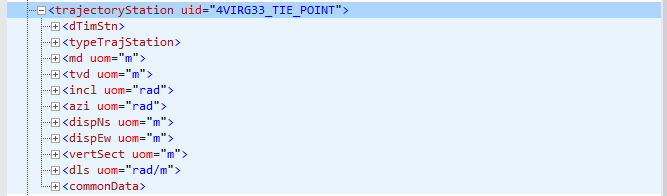
Figure 1: trajectoryStation with incomplete variables
Note that on the right of trajectoryStation there is a keyword named uid. As we saw before on the root node, the label on the right is called an attribute of the node. In this particular case, that uid is the unique identifier or uid of that measurement point. Keep in mind that all of them are unique.
Another interesting finding is that not all trajectoryStation nodes have the same number of variables. Compare the figure above (Fig. 1) with this coming from a similarly named node in Fig. 2:
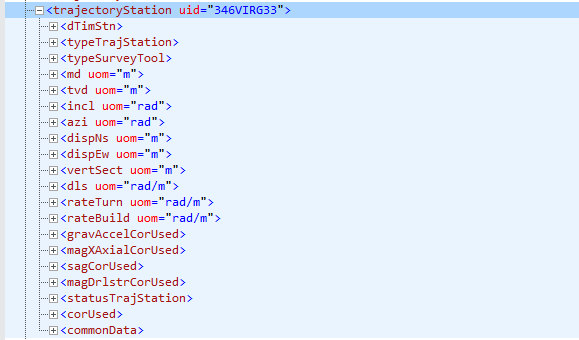
Figure 2: trajectoryStation node with all its variables
This hierarchical structure, as we can see, is very flexible. If there are not values, or measurements, they will not take space during storage. In tables or dataframes, they would usually be present but filled with NAs.
Reading a WITSML file
Now it’s time to get our hands dirty and do a bit of data science.
Loading the packages
We will use two packages: xml2, data.table and dplyr. xml2 will take care of reading the WITSML or XML files, while dplyr and data.table will be our workhorses for dataframe generation and data manipulation. I could have just used dplyr but I wanted to show you both table libraries. The other packages will be used at the end of the article for nesting structures and plotting.
# load libraries
library(data.table)
library(xml2)
library(dplyr)
library(tibble)
library(tidyr)
library(purrr)
library(ggplot2)List and load the XML files
- We are using a relatively WITSML small folder of 27 MB.
- The well pick is
Norway-Statoil-NO 15_$47$_9-F-9 - We show only show few of the XML files with their complete full name
all_files_xml <- list.files("./witsml", recursive = TRUE, full.names = TRUE,
include.dirs = TRUE, pattern = "*.xml")
# indices in R start at 1, not zero as in Python
all_files_xml[1:5]
#> [1] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/_wellInfo/NO 15_$47$_9-F-4 (5e023a7f-1b34-4948-81ca-286bba72793b).xml"
#> [2] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/1/_wellboreInfo/NO 15_$47$_9-F-4 (dbffce7a-74d8-4443-8b7e-b937e5fede95)(NULL).xml"
#> [3] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/1.xml"
#> [4] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/2.xml"
#> [5] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/1/bhaRun/3.xml"We could take a look at the number of XML files:
# how many XMLS files under the folder
length(all_files_xml)
#> [1] 230Select the trajectory file
# get the file for trajectory
traj_files <- grep(pattern = "trajectory", ignore.case = TRUE,
value = TRUE, x = all_files_xml)
traj_files
#> [1] "./witsml/Norway-Statoil-NO 15_$47$_9-F-4/1/trajectory/1.xml"
#> [2] "./witsml/Norway-Statoil-NO 15_$47$_9-F-7/1/trajectory/1.xml"
#> [3] "./witsml/Norway-Statoil-NO 15_$47$_9-F-9/1/trajectory/1.xml"Load the selected WITSML file
dat <- read_xml(traj_files[3])
dat_9f9 <- datRetrieve some information:
# some introspection
xml_name(dat)
#> [1] "trajectorys"
xml_children(dat)
#> {xml_nodeset (1)}
#> [1] <trajectory uidWell="432612d4-7a1b-464d-b89a-9783d4606a96" uidWellbore="d ...
# name of the child node
xml_name(xml_children(dat))
#> [1] "trajectory"
xml_name(xml_child(dat))
#> [1] "trajectory"Some introspection of the XML object
First 25 nodes
# strip default namespaces from the document
xml_ns_strip( dat )
all_nodes <- dat %>%
xml_find_all( '//*') %>%
xml_path()
all_nodes[1:25] # show only the first elements
#> [1] "/trajectorys"
#> [2] "/trajectorys/trajectory"
#> [3] "/trajectorys/trajectory/nameWell"
#> [4] "/trajectorys/trajectory/nameWellbore"
#> [5] "/trajectorys/trajectory/name"
#> [6] "/trajectorys/trajectory/objectGrowing"
#> [7] "/trajectorys/trajectory/dTimTrajStart"
#> [8] "/trajectorys/trajectory/dTimTrajEnd"
#> [9] "/trajectorys/trajectory/mdMn"
#> [10] "/trajectorys/trajectory/mdMx"
#> [11] "/trajectorys/trajectory/magDeclUsed"
#> [12] "/trajectorys/trajectory/gridCorUsed"
#> [13] "/trajectorys/trajectory/aziVertSect"
#> [14] "/trajectorys/trajectory/dispNsVertSectOrig"
#> [15] "/trajectorys/trajectory/dispEwVertSectOrig"
#> [16] "/trajectorys/trajectory/aziRef"
#> [17] "/trajectorys/trajectory/trajectoryStation[1]"
#> [18] "/trajectorys/trajectory/trajectoryStation[1]/dTimStn"
#> [19] "/trajectorys/trajectory/trajectoryStation[1]/typeTrajStation"
#> [20] "/trajectorys/trajectory/trajectoryStation[1]/md"
#> [21] "/trajectorys/trajectory/trajectoryStation[1]/tvd"
#> [22] "/trajectorys/trajectory/trajectoryStation[1]/incl"
#> [23] "/trajectorys/trajectory/trajectoryStation[1]/azi"
#> [24] "/trajectorys/trajectory/trajectoryStation[1]/dispNs"
#> [25] "/trajectorys/trajectory/trajectoryStation[1]/dispEw"Total number of nodes
# get the number of elements
dat <- xml_ns_strip( dat )
noe <- dat %>%
xml_find_all( '//*') %>%
xml_path() %>%
length()
noe
#> [1] 712Last 25 nodes
# let's see the last 25
tail(all_nodes, 25)
#> [1] "/trajectorys/trajectory/trajectoryStation[25]/dls"
#> [2] "/trajectorys/trajectory/trajectoryStation[25]/rateTurn"
#> [3] "/trajectorys/trajectory/trajectoryStation[25]/rateBuild"
#> [4] "/trajectorys/trajectory/trajectoryStation[25]/gravAccelCorUsed"
#> [5] "/trajectorys/trajectory/trajectoryStation[25]/magXAxialCorUsed"
#> [6] "/trajectorys/trajectory/trajectoryStation[25]/sagCorUsed"
#> [7] "/trajectorys/trajectory/trajectoryStation[25]/magDrlstrCorUsed"
#> [8] "/trajectorys/trajectory/trajectoryStation[25]/statusTrajStation"
#> [9] "/trajectorys/trajectory/trajectoryStation[25]/corUsed"
#> [10] "/trajectorys/trajectory/trajectoryStation[25]/corUsed/stnGridCorUsed"
#> [11] "/trajectorys/trajectory/trajectoryStation[25]/corUsed/dirSensorOffset"
#> [12] "/trajectorys/trajectory/trajectoryStation[25]/commonData"
#> [13] "/trajectorys/trajectory/trajectoryStation[25]/commonData/sourceName"
#> [14] "/trajectorys/trajectory/trajectoryStation[25]/commonData/dTimCreation"
#> [15] "/trajectorys/trajectory/trajectoryStation[25]/commonData/dTimLastChange"
#> [16] "/trajectorys/trajectory/trajectoryStation[25]/commonData/itemState"
#> [17] "/trajectorys/trajectory/trajectoryStation[25]/commonData/priv_customData"
#> [18] "/trajectorys/trajectory/commonData"
#> [19] "/trajectorys/trajectory/commonData/sourceName"
#> [20] "/trajectorys/trajectory/commonData/dTimCreation"
#> [21] "/trajectorys/trajectory/commonData/dTimLastChange"
#> [22] "/trajectorys/trajectory/commonData/itemState"
#> [23] "/trajectorys/trajectory/commonData/priv_userOwner"
#> [24] "/trajectorys/trajectory/commonData/priv_ipOwner"
#> [25] "/trajectorys/trajectory/commonData/priv_dTimReceived"Getting data from nodes and subnodes
As we described succintly above there are four main groups of nodes that we are interested in:
- The root node
- The
trajectorynode - The measurements node
trajectoryStationand subnodes - The siblings of the measurements nodes
Our task is putting together all the variables and their corresponding values in a data structure that we are familiar with: a table. This step may not totally necessary if we have the proper software or tools that do the collection and search in the background for us. For the time being, let’s take like it were a data anatomy lesson.
The root node, trajectorys
This is the parent of the trajectory node. It carries not so meaningful information that I can see.
# attributes for the root node
trajectorys <- xml_find_first( dat, "//trajectorys")
xml_attrs(trajectorys)
#> version
#> "1.4.1.1"
#> xmlns:xsi
#> "http://www.w3.org/2001/XMLSchema-instance"
xml_name(trajectorys)
#> [1] "trajectorys"
xml_siblings(trajectorys) # no siblings because it is the root
#> {xml_nodeset (0)}The trajectory node
trajectory summary
The trajectory node has two sub-levels of nodes: the measurement nodes (trajectoryStation) and the siblings that carry metadata for the trajectoryStation nodes.
# attributes of the trajectory node
trajectory <- xml_find_first( dat, "//trajectory")
xml_attrs(trajectory)
#> uidWell uidWellbore
#> "432612d4-7a1b-464d-b89a-9783d4606a96" "d1c7a0d7-afa6-487e-aa4a-e34adc091a9c"
#> uid
#> "4VIRG33"
# names of the parent node
xml_name(xml_parent(trajectory))
#> [1] "trajectorys"
# name of the current node
xml_name(trajectory)
#> [1] "trajectory"# name of the child nodes
xml_name(xml_children(trajectory))
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef" "trajectoryStation"
#> [16] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [19] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [22] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [25] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [28] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [31] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [34] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [37] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [40] "commonData"trajectory children. Method 1
# trajectoryStation children nodes
xml_name(xml_children(xml_find_all(dat, "//trajectorys/trajectory" )))
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef" "trajectoryStation"
#> [16] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [19] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [22] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [25] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [28] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [31] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [34] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [37] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [40] "commonData"At this point we don’t know which node has children or dependents.
Total number of nodes under trajectory
# number of trajectoryStation children nodes
length(xml_name(xml_children(xml_find_all(dat, "//trajectorys/trajectory" ))))
#> [1] 40trajectory children. Method 2
# another way of obtaining the names of the nodes for "trajectory"
xml_name(xml_children(xml_find_first(dat, "//trajectory")))
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef" "trajectoryStation"
#> [16] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [19] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [22] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [25] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [28] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [31] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [34] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [37] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [40] "commonData"trajectory childless nodes (with spec)
If we know by specification that a node does not have dependent nodes then we could manually indicate the indices in the vector containing their names. This requires having at hand the specification or a manual inspection node by node.
# name of the orphan nodes
orphan_vars <- c(1:14) # indices are being set manually.
# not a very practical solution
# the first 14 children of trajectory
vars14_names <- xml_name(xml_children(xml_find_first(dat,
"//trajectory")))[orphan_vars]
vars14_names
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef"Later we will find a better way of getting the nodes with no dependents by building a function of our own.
trajectory children. Method 3
# get all the nodes
xml_children(dat) %>% # trajectory
xml_children() %>% # variables and values of the children
xml_name() # names of the variables only
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef" "trajectoryStation"
#> [16] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [19] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [22] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [25] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [28] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [31] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [34] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [37] "trajectoryStation" "trajectoryStation" "trajectoryStation"
#> [40] "commonData"Building the function get_variables_under_node()
#' Get the names of variables under a node
#'
#' @param xml_dat a XML document
#' @param node a node of the form parent_node\child_node
#'
#' @return a character vector with the names of the variables
#' @export
#'
#' @examples
get_variables_under_node <- function(xml_dat, node) {
xpath <- paste("//", node)
xml_find_all(xml_dat, xpath) %>%
xml_children() %>%
xml_name() %>%
unique()
}Getting all variables under a specific node
# test the function get_variables_under_node()
get_variables_under_node(dat, "trajectory")
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef" "trajectoryStation"
#> [16] "commonData"get_variables_under_node(dat, "trajectory/trajectoryStation")
#> [1] "dTimStn" "typeTrajStation" "md"
#> [4] "tvd" "incl" "azi"
#> [7] "dispNs" "dispEw" "vertSect"
#> [10] "dls" "commonData" "typeSurveyTool"
#> [13] "rateTurn" "rateBuild" "gravAccelCorUsed"
#> [16] "magXAxialCorUsed" "sagCorUsed" "magDrlstrCorUsed"
#> [19] "statusTrajStation" "corUsed"Build the functions how_many_children, have_children
This is the function we were looking for. A way to check if the nodes under trajectory, or any node, have children.
#' How many children does a parent node have
#'
#' Returns a character vector with the name of the vector and the node count
#' @param xml_dat a XML document
#' @param node a node of the form parent_node\child_node
#'
how_many_children <- function(xml_dat, node) {
vars_vector <- vector("integer")
var_names <- get_variables_under_node(xml_dat, node)
i <- 1
for (var in var_names) {
xpath <- paste("//", node, "/", var)
num_children <- max(xml_length(xml_find_all(xml_dat, xpath)))
vars_vector[i] <- num_children
names(vars_vector)[i] <- var
# cat(i, var, vars_vector[i], "\n")
i <- i + 1
}
vars_vector
}Testing the function how_many_children.
# test the function how_many_children()
how_many_children(dat, "trajectory")
#> nameWell nameWellbore name objectGrowing
#> 0 0 0 0
#> dTimTrajStart dTimTrajEnd mdMn mdMx
#> 0 0 0 0
#> magDeclUsed gridCorUsed aziVertSect dispNsVertSectOrig
#> 0 0 0 0
#> dispEwVertSectOrig aziRef trajectoryStation commonData
#> 0 0 20 7Note that only two variables have children or dependents.
Build the functions have_children and have_no_children
#' Get a vector of those nodes that have children and their count
#'
#' @param xml_dat
#' @param node
#'
have_children <- function(xml_dat, node) {
how_many <- how_many_children(xml_dat, node)
how_many[how_many > 0]
}
#' Get a vector of those nodes that do not have children and their zero count.
#'
#' @param xml_dat
#' @param node
#'
have_no_children <- function(xml_dat, node) {
how_many <- how_many_children(xml_dat, node)
how_many[how_many == 0]
}test for nodes and dependents
Now we can easily find what nodes are childless
have_no_children(dat, "trajectory")
#> nameWell nameWellbore name objectGrowing
#> 0 0 0 0
#> dTimTrajStart dTimTrajEnd mdMn mdMx
#> 0 0 0 0
#> magDeclUsed gridCorUsed aziVertSect dispNsVertSectOrig
#> 0 0 0 0
#> dispEwVertSectOrig aziRef
#> 0 0List only the names of the variables that have no children.
names(have_no_children(dat, "trajectory"))
#> [1] "nameWell" "nameWellbore" "name"
#> [4] "objectGrowing" "dTimTrajStart" "dTimTrajEnd"
#> [7] "mdMn" "mdMx" "magDeclUsed"
#> [10] "gridCorUsed" "aziVertSect" "dispNsVertSectOrig"
#> [13] "dispEwVertSectOrig" "aziRef"Nodes under //trajectory/trajectoryStation
Get trajectoryStation children. Method 1
# names of the children for "trajectoryStation"
xml_name(xml_children(xml_find_first( dat, "//trajectory/trajectoryStation")))
#> [1] "dTimStn" "typeTrajStation" "md" "tvd"
#> [5] "incl" "azi" "dispNs" "dispEw"
#> [9] "vertSect" "dls" "commonData"Get trajectoryStation children. Method 2
This yields the same result:
# names of the nodes for "trajectoryStation"
xml_name(xml_children(xml_find_first(dat, "//trajectoryStation")))
#> [1] "dTimStn" "typeTrajStation" "md" "tvd"
#> [5] "incl" "azi" "dispNs" "dispEw"
#> [9] "vertSect" "dls" "commonData"Get attributes of trajectoryStation
# find attributes of the first element of trajectoryStation found
trajectoryStation <- xml_find_first(dat, "//trajectoryStation")
xml_attrs(x = trajectoryStation)
#> uid
#> "4VIRG33_TIE_POINT"number of measurement stations
# find all observations for dTimStn
trajectoryStation.dTimStn <- xml_find_all(dat, "//trajectoryStation/dTimStn")
# we end up finding a way to calculate the number of trajectory stations
length(trajectoryStation.dTimStn)
#> [1] 25Why the variables under trajectoryStation are different
Pay attention to these two cases when we interrogate about the name of the variables under trajectoryStation.
This is asking for variables in the first node:
# name of the dependent nodes of "trajectoryStation"
xml_name(xml_children(xml_find_first(dat, "//trajectoryStation")))
#> [1] "dTimStn" "typeTrajStation" "md" "tvd"
#> [5] "incl" "azi" "dispNs" "dispEw"
#> [9] "vertSect" "dls" "commonData"This is asking for variables for all the nodes and taking only the unique names, those that do not repeat:
# name of the dependent nodes of "trajectoryStation"
unique(xml_name(xml_children(xml_find_all(dat, "//trajectoryStation"))))
#> [1] "dTimStn" "typeTrajStation" "md"
#> [4] "tvd" "incl" "azi"
#> [7] "dispNs" "dispEw" "vertSect"
#> [10] "dls" "commonData" "typeSurveyTool"
#> [13] "rateTurn" "rateBuild" "gravAccelCorUsed"
#> [16] "magXAxialCorUsed" "sagCorUsed" "magDrlstrCorUsed"
#> [19] "statusTrajStation" "corUsed"Note. They are different because in the first case we are asking for the first node (
xml_find_first) while in the second case we are asking for all the nodes (xml_find_all). This is normal. The reason of existence of hierarchical structures that doesn’t waste space in variables that are not currently used.
Attributes of trajectoryStation
# get the attributes for trajectoryStation
xml_attrs(x = trajectoryStation)
#> uid
#> "4VIRG33_TIE_POINT"
# we get only the "uid" attribute# get the value of the attribute we found
xml_attr(x = trajectoryStation, attr = "uid")
#> [1] "4VIRG33_TIE_POINT"commonData: names and values
There are two type of nodes with the same name but hang from different parents:
* //trajectory/commonData
* //trajectoryStation/commonData
Both have different purposes.
//trajectory/commonData
Nodes under //trajectory/commonData:
# get the subnodes for //trajectory/commonData
unique(xml_name(xml_children(xml_find_all(dat, "//trajectory/commonData"))))
#> [1] "sourceName" "dTimCreation" "dTimLastChange"
#> [4] "itemState" "priv_userOwner" "priv_ipOwner"
#> [7] "priv_dTimReceived"Number of nodes under //trajectory/commonData:
# number of subnodes
max(xml_length(xml_find_all(dat, "//trajectory/commonData")))
#> [1] 7Values for the nodes under //trajectory/commonData:
# values for the first macthing node
xml_text((xml_find_first(dat, "//trajectory/commonData" ) ) )
#> [1] "Baker Hughes2016-09-29T03:43:41.342Z2016-09-29T03:43:41.342Zactualsc-sync-bhi143.97.229.42016-09-29T03:43:41.342Z"//trajectoryStation/commonData
Nodes under //trajectoryStation/commonData:
# get the subnodes for //trajectoryStation/commonData
unique(xml_name(xml_children(xml_find_all(dat, "//trajectoryStation/commonData" ) ) ))
#> [1] "sourceName" "dTimCreation" "dTimLastChange" "itemState"
#> [5] "priv_customData"Number of nodes under //trajectoryStation/commonData:
# number of subnodes for //trajectoryStation/commonData
# we use max() for the case it returns a vector with multiple nodes and lengths
max(xml_length(xml_find_all(dat, "//trajectoryStation/commonData")))
#> [1] 5Values for the nodes under //trajectoryStation/commonData:
# values for the first matching node
xml_text((xml_find_first(dat, "//trajectoryStation/commonData" ) ) )
#> [1] "Baker Hughes2016-09-29T03:43:41.342Z2016-09-29T03:43:41.342Zactual"Creating the dataframes
At this point we have figured out how to extract the names and values from nodes in a hirerarchical structure. Now, it is time to build the tables with that data.
trajectory dataframe
# get all attributes for trajectory node
# we try with datatable and dataframe
trajectory <- xml_find_first( dat, "//trajectory")
trajectory <- xml_attrs(trajectory)
trajectory_attr_dt <- data.table(t(trajectory))
trajectory_attr_df <- data.frame(t(trajectory), stringsAsFactors = FALSE)
trajectory_attr_df
#> uidWell uidWellbore
#> 1 432612d4-7a1b-464d-b89a-9783d4606a96 d1c7a0d7-afa6-487e-aa4a-e34adc091a9c
#> uid
#> 1 4VIRG33# This is the same way of getting a dataframe for trajectory
# get values for all the attributes of the trajectory node
# using magrittr
xml_find_first( dat, "//trajectory") %>%
xml_attrs() %>%
t() %>%
data.frame(stringsAsFactors = FALSE)
#> uidWell uidWellbore
#> 1 432612d4-7a1b-464d-b89a-9783d4606a96 d1c7a0d7-afa6-487e-aa4a-e34adc091a9c
#> uid
#> 1 4VIRG33Siblings of trajectoryStation
This takes only one row.
# get all the trajectory variables, with and without descendants
trajectory_children <- xml_name(xml_children(xml_find_first(dat, "//trajectory")))
# get only those variables without descendants. hnc: have no children
traj_hnc_names <- names(have_no_children(dat, "trajectory"))
traj_hnc_idx <- which(trajectory_children %in% traj_hnc_names)
traj_hnc <- xml_text(xml_children(xml_find_first( dat, "//trajectory")))[traj_hnc_idx]
names(traj_hnc) <- traj_hnc_names
# dataframe and datatable
siblings_df <- data.frame(t(traj_hnc), stringsAsFactors = FALSE)
siblings_df
#> nameWell nameWellbore name objectGrowing
#> 1 NO 15/9-F-9 NO 15/9-F-9 A MWD-15/9-F-9 A false
#> dTimTrajStart dTimTrajEnd mdMn mdMx magDeclUsed
#> 1 2016-09-28T23:59:57.000Z 2016-09-29T00:03:50.000Z 0 1206 0
#> gridCorUsed aziVertSect dispNsVertSectOrig dispEwVertSectOrig aziRef
#> 1 0 0 0 0 true north
siblings_dt <- data.table(t(traj_hnc))combine trajectory and siblings in a one-row dataframe
We use the function cbind to glue the columns together.
trajectory_dt <- cbind(trajectory_attr_dt, siblings_dt)
trajectory_df <- cbind(trajectory_attr_df, siblings_df)# print the table
print(as_tibble(trajectory_df))
#> # A tibble: 1 × 17
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 432612d4-7a… d1c7a0d7-afa6-… 4VIRG… NO 15/9… NO 15/9-F-9… MWD-1… false
#> # … with 10 more variables: dTimTrajStart <chr>, dTimTrajEnd <chr>, mdMn <chr>,
#> # mdMx <chr>, magDeclUsed <chr>, gridCorUsed <chr>, aziVertSect <chr>,
#> # dispNsVertSectOrig <chr>, dispEwVertSectOrig <chr>, aziRef <chr>trajectoryStation measurements
Part 1 of 4 of the trajectoryStation dataframe
Corresponds to the dataframe for the trajectoryStation attribute uid.
# get values for uid attribute of trajectoryStation
# these are the well ids
tS.uid <- dat %>%
xml_find_all("//trajectoryStation") %>%
xml_attr("uid")
tS.uid_dt <- data.table(uid = tS.uid)
tS.uid_df <- data.frame(uid = tS.uid, stringsAsFactors = FALSE)
tS.uid_df
#> uid
#> 1 4VIRG33_TIE_POINT
#> 2 325VIRG33
#> 3 326VIRG33
#> 4 327VIRG33
#> 5 328VIRG33
#> 6 329VIRG33
#> 7 330VIRG33
#> 8 331VIRG33
#> 9 332VIRG33
#> 10 333VIRG33
#> 11 334VIRG33
#> 12 335VIRG33
#> 13 336VIRG33
#> 14 337VIRG33
#> 15 338VIRG33
#> 16 339VIRG33
#> 17 340VIRG33
#> 18 341VIRG33
#> 19 342VIRG33
#> 20 343VIRG33
#> 21 344VIRG33
#> 22 345VIRG33
#> 23 346VIRG33
#> 24 347VIRG33
#> 25 348VIRG33We could use this method to create a function that finds the number of observations, or rows, for trajectoryStation:
# get the number of rows for a parent node
#' Get the number of rows for a parent node.
#'
#' @param xml_dat the xml document
#' @param parent_node a node without the two forward slashes
#' @param attribute the attribute of the node if available
#'
#' @return
#' @export
#'
#' @examples
get_numrows_parent_node <- function(xml_dat, parent_node, attribute) {
# TODO: validate if the node has an attribute
xml_dat %>%
xml_find_all(paste("//", parent_node)) %>%
xml_attr("uid") %>%
length()
}
# exercise the function
parent <- "trajectoryStation"
attrib <- "uid"
get_numrows_parent_node(dat, parent, attrib)
#> [1] 25measurement stations or trajectoryStation
# using xml_children
# we also get commonData which has children
trajectoryStation_all_names <- xml_name(xml_children(xml_find_all(dat,
"//trajectoryStation")))
trajectoryStation_all_names <- unique(trajectoryStation_all_names)
trajectoryStation_all_names
#> [1] "dTimStn" "typeTrajStation" "md"
#> [4] "tvd" "incl" "azi"
#> [7] "dispNs" "dispEw" "vertSect"
#> [10] "dls" "commonData" "typeSurveyTool"
#> [13] "rateTurn" "rateBuild" "gravAccelCorUsed"
#> [16] "magXAxialCorUsed" "sagCorUsed" "magDrlstrCorUsed"
#> [19] "statusTrajStation" "corUsed"# get the number of columns by name
# commonData is excluded (but we know that in advance)
no_commonData <- which(trajectoryStation_all_names %in% c("commonData"))
# get rid of commonData since it has children
trajectoryStation_names <- trajectoryStation_all_names[-no_commonData] # exclude
trajectoryStation_names
#> [1] "dTimStn" "typeTrajStation" "md"
#> [4] "tvd" "incl" "azi"
#> [7] "dispNs" "dispEw" "vertSect"
#> [10] "dls" "typeSurveyTool" "rateTurn"
#> [13] "rateBuild" "gravAccelCorUsed" "magXAxialCorUsed"
#> [16] "sagCorUsed" "magDrlstrCorUsed" "statusTrajStation"
#> [19] "corUsed"draft of a future function
# first non-automated way of getting values for the all the trajectoryStation nodes
# there are 19 variables under trajectoryStation, not including commonData which
# was manually removed
xml_dat <- dat
node <- "trajectoryStation"
max_obs <- get_numrows_parent_node(dat, "trajectoryStation", attribute = "uid")
var_names <- trajectoryStation_names # names of the variables in a vector
li_vars <- vector("list") # vector of list
for (var in var_names) { # iterate through all the variables
xpath <- paste("//", node, "/", var) # form the xpath
num_children <- max(xml_length(xml_find_all(dat, xpath)))
if (num_children == 0) { # skip if the node has children
value_xpath <- xml_text(xml_find_all(dat, xpath)) # get all the values
vx <- value_xpath # make it a shorter name
# if the variables are all not present, add NA. max=25
# cat(var, max_obs, length(vx), "\n")
if (length(vx) < max_obs) vx <- c(rep(NA, max_obs - length(vx)), vx)
li_vars[[var]] <- vx
}
}
tS_df <- as.data.frame(li_vars, stringsAsFactors = FALSE)# print the table for trajectoryStation
print(as_tibble(tS_df))
#> # A tibble: 25 × 18
#> dTimStn typeTrajStation md tvd incl azi dispNs dispEw vertSect dls
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2016-09… tie in point 0 0 0 0 0 0 0 0
#> 2 2016-09… gyro north see… 145.… 145.… 0 0 0 0 0 0
#> 3 2016-09… gyro north see… 218.5 218.… 0.00… 3.44… -0.15… -0.04… -0.1573… 6.25…
#> 4 2016-09… gyro north see… 259 258.… 0.00… 4.45… -0.26… -0.13… -0.2612… 9.68…
#> 5 2016-09… gyro north see… 299.5 299.… 0.00… 4.20… -0.33… -0.30… -0.3375… 7.81…
#> 6 2016-09… gyro north see… 340 339.… 0.00… 0.61… -0.27… -0.32… -0.2703… 0.00…
#> 7 2016-09… gyro north see… 394.… 394.… 0.00… 6.00… 0.060… -0.25… 0.06012… 0.00…
#> 8 2016-09… gyro north see… 420.… 420.… 0.00… 6.15… 0.215… -0.28… 0.21588… 3.48…
#> 9 2016-09… gyro north see… 454.… 454.… 0.08… 3.45… -1.01… -0.72… -1.0151… 0.00…
#> 10 2016-09… gyro north see… 497.… 497.… 0.15… 3.48… -5.80… -2.36… -5.8030… 0.00…
#> # … with 15 more rows, and 8 more variables: typeSurveyTool <chr>,
#> # rateTurn <chr>, rateBuild <chr>, gravAccelCorUsed <chr>,
#> # magXAxialCorUsed <chr>, sagCorUsed <chr>, magDrlstrCorUsed <chr>,
#> # statusTrajStation <chr>names(tS_df)
#> [1] "dTimStn" "typeTrajStation" "md"
#> [4] "tvd" "incl" "azi"
#> [7] "dispNs" "dispEw" "vertSect"
#> [10] "dls" "typeSurveyTool" "rateTurn"
#> [13] "rateBuild" "gravAccelCorUsed" "magXAxialCorUsed"
#> [16] "sagCorUsed" "magDrlstrCorUsed" "statusTrajStation"# get the names of variables under a node
get_variables_under_node <- function(xml_dat, node) {
xpath <- paste("//", node)
xml_find_all(xml_dat, xpath) %>%
xml_children() %>%
xml_name() %>%
unique()
}
tS.cD_names <- get_variables_under_node(dat, "trajectoryStation/commonData")
tS.cD_names
#> [1] "sourceName" "dTimCreation" "dTimLastChange" "itemState"
#> [5] "priv_customData"# get variables under trajectoryStation
# detect what variables are standalone and which ones have children
how_many_children(dat, "trajectoryStation")
#> dTimStn typeTrajStation md tvd
#> 0 0 0 0
#> incl azi dispNs dispEw
#> 0 0 0 0
#> vertSect dls commonData typeSurveyTool
#> 0 0 5 0
#> rateTurn rateBuild gravAccelCorUsed magXAxialCorUsed
#> 0 0 0 0
#> sagCorUsed magDrlstrCorUsed statusTrajStation corUsed
#> 0 0 0 2There are two variables under trajectoryStation that have descendants.
Build the function nodes_as_df
#' Converts children of a node and their values to a dataframe.
#' Receives a node (do not add '//'), creates a vector with the variables under
#' the node, iterates through each of the variables, fills uneven rows with NAs.
#' It will skip a child node that contains children.
#'
#' @param xml_dat a xml document
#' @param node a node of the form "trajectoryStation/dTimStn". No need to add "//"
#' @param max_obs
nodes_as_df <- function(xml_dat, node, max_obs) {
li_vars <- vector("list") # vector of list
var_names <- get_variables_under_node(xml_dat, node)
for (var in var_names) { # iterate through all the variables
xpath <- paste("//", node, "/", var) # form the xpath
num_children <- max(xml_length(xml_find_all(xml_dat, xpath)))
if (num_children == 0) { # skip if the node has children
value_xpath <- xml_text(xml_find_all(xml_dat, xpath)) # get all the values
vx <- value_xpath # make it a shorter name
# if the variables are all not present, add NA. max=25
# cat(var, max_obs, length(vx), "\n")
if (length(vx) < max_obs) vx <- c(rep(NA, max_obs - length(vx)), vx)
li_vars[[var]] <- vx
}
}
as.data.frame(li_vars, stringsAsFactors = FALSE)
}Part 2 of 4 of the trajectoryStation dataframe
# using function get_numrows_parent_node()
num_trajectoryStation <- get_numrows_parent_node(dat, "trajectoryStation",
attribute = "uid")
tS.trajectoryStation_df <- nodes_as_df(dat, "trajectoryStation", num_trajectoryStation)
as_tibble(tS.trajectoryStation_df)
#> # A tibble: 25 × 18
#> dTimStn typeTrajStation md tvd incl azi dispNs dispEw vertSect dls
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2016-09… tie in point 0 0 0 0 0 0 0 0
#> 2 2016-09… gyro north see… 145.… 145.… 0 0 0 0 0 0
#> 3 2016-09… gyro north see… 218.5 218.… 0.00… 3.44… -0.15… -0.04… -0.1573… 6.25…
#> 4 2016-09… gyro north see… 259 258.… 0.00… 4.45… -0.26… -0.13… -0.2612… 9.68…
#> 5 2016-09… gyro north see… 299.5 299.… 0.00… 4.20… -0.33… -0.30… -0.3375… 7.81…
#> 6 2016-09… gyro north see… 340 339.… 0.00… 0.61… -0.27… -0.32… -0.2703… 0.00…
#> 7 2016-09… gyro north see… 394.… 394.… 0.00… 6.00… 0.060… -0.25… 0.06012… 0.00…
#> 8 2016-09… gyro north see… 420.… 420.… 0.00… 6.15… 0.215… -0.28… 0.21588… 3.48…
#> 9 2016-09… gyro north see… 454.… 454.… 0.08… 3.45… -1.01… -0.72… -1.0151… 0.00…
#> 10 2016-09… gyro north see… 497.… 497.… 0.15… 3.48… -5.80… -2.36… -5.8030… 0.00…
#> # … with 15 more rows, and 8 more variables: typeSurveyTool <chr>,
#> # rateTurn <chr>, rateBuild <chr>, gravAccelCorUsed <chr>,
#> # magXAxialCorUsed <chr>, sagCorUsed <chr>, magDrlstrCorUsed <chr>,
#> # statusTrajStation <chr>Part 3 of 4 of the trajectoryStation dataframe: commonData
Correspond to the dataframe of trajectoryStation/commonData.
# cascading way
xpath <- "//trajectoryStation/commonData"
xml_find_all(dat, xpath) %>%
xml_children() %>%
xml_name() %>%
unique()
#> [1] "sourceName" "dTimCreation" "dTimLastChange" "itemState"
#> [5] "priv_customData"# get the nodes under trajectoryStation/commonData
tS.cD_df <- nodes_as_df(xml_dat, node = "trajectoryStation/commonData", max_obs = 25)
as_tibble(tS.cD_df)
#> # A tibble: 25 × 5
#> sourceName dTimCreation dTimLastChange itemState priv_customData
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual <NA>
#> 2 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 3 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 4 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 5 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 6 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 7 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 8 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 9 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> 10 Baker Hughes 2016-09-29T03:43:41.342Z 2016-09-29T03… actual SurveyQC=3,Sur…
#> # … with 15 more rowsPart 4 of 4 of the trajectoryStation dataframe: corUsed
# cascading way
xpath <- "//trajectoryStation/corUsed"
xml_find_all(dat, xpath) %>%
xml_children() %>%
xml_name() %>%
unique()
#> [1] "stnGridCorUsed" "dirSensorOffset"
# get the nodes under trajectoryStation/commonData
tS.cU_df <- nodes_as_df(xml_dat, node = "trajectoryStation/corUsed", max_obs = 25)
as_tibble(tS.cU_df)
#> # A tibble: 25 × 2
#> stnGridCorUsed dirSensorOffset
#> <chr> <chr>
#> 1 <NA> <NA>
#> 2 999.25 0
#> 3 999.25 0
#> 4 999.25 0
#> 5 999.25 0
#> 6 999.25 0
#> 7 999.25 0
#> 8 999.25 0
#> 9 999.25 0
#> 10 999.25 0
#> # … with 15 more rowsCombined dataframe for trajectoryStation
Combination of:
- uid attribute
- measurement stations data
commonData, which originally had childrencorUsed, also with children nodes
# combine all dataframes to make up trajectoryStation dataframe
# tS.uid_dt: trajectoryStation attributes
# tS_df: trajectoryStation data
# tS.cD_df: commonData
trajectoryStation_df <- cbind(tS.uid_dt,
tS_df,
tS.cU_df,
tS.cD_df)
trajectoryStation_dt <- data.table(trajectoryStation_df)# print the combined table for trajectoryStation
print(as_tibble(trajectoryStation_df))
#> # A tibble: 25 × 26
#> uid dTimStn typeTrajStation md tvd incl azi dispNs dispEw vertSect
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 4VIRG… 2016-0… tie in point 0 0 0 0 0 0 0
#> 2 325VI… 2016-0… gyro north see… 145.… 145.… 0 0 0 0 0
#> 3 326VI… 2016-0… gyro north see… 218.5 218.… 0.00… 3.44… -0.15… -0.04… -0.1573…
#> 4 327VI… 2016-0… gyro north see… 259 258.… 0.00… 4.45… -0.26… -0.13… -0.2612…
#> 5 328VI… 2016-0… gyro north see… 299.5 299.… 0.00… 4.20… -0.33… -0.30… -0.3375…
#> 6 329VI… 2016-0… gyro north see… 340 339.… 0.00… 0.61… -0.27… -0.32… -0.2703…
#> 7 330VI… 2016-0… gyro north see… 394.… 394.… 0.00… 6.00… 0.060… -0.25… 0.06012…
#> 8 331VI… 2016-0… gyro north see… 420.… 420.… 0.00… 6.15… 0.215… -0.28… 0.21588…
#> 9 332VI… 2016-0… gyro north see… 454.… 454.… 0.08… 3.45… -1.01… -0.72… -1.0151…
#> 10 333VI… 2016-0… gyro north see… 497.… 497.… 0.15… 3.48… -5.80… -2.36… -5.8030…
#> # … with 15 more rows, and 16 more variables: dls <chr>, typeSurveyTool <chr>,
#> # rateTurn <chr>, rateBuild <chr>, gravAccelCorUsed <chr>,
#> # magXAxialCorUsed <chr>, sagCorUsed <chr>, magDrlstrCorUsed <chr>,
#> # statusTrajStation <chr>, stnGridCorUsed <chr>, dirSensorOffset <chr>,
#> # sourceName <chr>, dTimCreation <chr>, dTimLastChange <chr>,
#> # itemState <chr>, priv_customData <chr>Add an id for the tables relationship
# create a new column id for relationship to another table
id <- trajectoryStation_df[1, uid]
sub_id <- gsub(pattern = "_.*$", replacement = "", x = id)
sub_id
#> [1] "4VIRG33"
trajectoryStation_df <- trajectoryStation_df %>%
mutate(id = sub_id) %>%
select(id, everything()) %>%
as_tibble()
trajectoryStation_dt = data.table(trajectoryStation_df)# chracateristics of the table
dim(trajectoryStation_dt)
#> [1] 25 27
names(trajectoryStation_dt)
#> [1] "id" "uid" "dTimStn"
#> [4] "typeTrajStation" "md" "tvd"
#> [7] "incl" "azi" "dispNs"
#> [10] "dispEw" "vertSect" "dls"
#> [13] "typeSurveyTool" "rateTurn" "rateBuild"
#> [16] "gravAccelCorUsed" "magXAxialCorUsed" "sagCorUsed"
#> [19] "magDrlstrCorUsed" "statusTrajStation" "stnGridCorUsed"
#> [22] "dirSensorOffset" "sourceName" "dTimCreation"
#> [25] "dTimLastChange" "itemState" "priv_customData"
# TODO: decompose corUsed and add it to the dataframePutting all together
print(as_tibble(trajectory_dt))
#> # A tibble: 1 × 17
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 432612d4-7a… d1c7a0d7-afa6-… 4VIRG… NO 15/9… NO 15/9-F-9… MWD-1… false
#> # … with 10 more variables: dTimTrajStart <chr>, dTimTrajEnd <chr>, mdMn <chr>,
#> # mdMx <chr>, magDeclUsed <chr>, gridCorUsed <chr>, aziVertSect <chr>,
#> # dispNsVertSectOrig <chr>, dispEwVertSectOrig <chr>, aziRef <chr>We have one interesting thing going on. We have the trajectory dataframe that is one row and 17 columns (1x17), while trajectoryStation is 25 rows by 27 columns (25x27). How do we work them out in rectangular tables?
We will have to join them. We will use an inner join in data.table.
Join trajectory and trajectoryStation dataframes
setkey(trajectory_dt, uid)
setkey(trajectoryStation_dt, id)
# inner join
t_9f9_dt <- trajectory_dt[trajectoryStation_dt, nomatch=0] %>%
as_tibble() %>%
print()
#> # A tibble: 25 × 43
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 2 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 3 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 4 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 5 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 6 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 7 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 8 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 9 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> 10 432612d4-7a… d1c7a0d7-afa6-… 4VIR… NO 15/9… NO 15/9-F-9… MWD-1… false
#> # … with 15 more rows, and 36 more variables: dTimTrajStart <chr>,
#> # dTimTrajEnd <chr>, mdMn <chr>, mdMx <chr>, magDeclUsed <chr>,
#> # gridCorUsed <chr>, aziVertSect <chr>, dispNsVertSectOrig <chr>,
#> # dispEwVertSectOrig <chr>, aziRef <chr>, i.uid <chr>, dTimStn <chr>,
#> # typeTrajStation <chr>, md <chr>, tvd <chr>, incl <chr>, azi <chr>,
#> # dispNs <chr>, dispEw <chr>, vertSect <chr>, dls <chr>,
#> # typeSurveyTool <chr>, rateTurn <chr>, rateBuild <chr>, …
well_9f9_df <- t_9f9_dtnames(trajectoryStation_dt)
#> [1] "id" "uid" "dTimStn"
#> [4] "typeTrajStation" "md" "tvd"
#> [7] "incl" "azi" "dispNs"
#> [10] "dispEw" "vertSect" "dls"
#> [13] "typeSurveyTool" "rateTurn" "rateBuild"
#> [16] "gravAccelCorUsed" "magXAxialCorUsed" "sagCorUsed"
#> [19] "magDrlstrCorUsed" "statusTrajStation" "stnGridCorUsed"
#> [22] "dirSensorOffset" "sourceName" "dTimCreation"
#> [25] "dTimLastChange" "itemState" "priv_customData"Apply the functions on a second well
Now, this should take less time.
all_files_xml <- list.files("./witsml", recursive = TRUE, full.names = TRUE,
include.dirs = TRUE, pattern = "*.xml")
# Select the trajectory file
# get the file for trajectory
traj_files <- grep(pattern = "trajectory", ignore.case = TRUE,
value = TRUE, x = all_files_xml)
dat_9f7 <- read_xml(traj_files[2])Total number of nodes for the 2nd well
get_total_number_of_nodes <- function(xml_dat) {
# get the number of elements
dat <- xml_ns_strip(xml_dat)
noe <- xml_dat %>%
xml_find_all( '//*') %>%
xml_path() %>%
length()
noe
}
get_total_number_of_nodes(dat_9f7)
#> [1] 1190trajectory dataframe for the 2nd well
get_trajectory_attributes_df <- function(xml_dat) {
xml_find_first(xml_dat, "//trajectory") %>%
xml_attrs() %>%
t() %>%
data.frame(stringsAsFactors = FALSE)
}
# function
get_trajectory_metadata <- function(xml_dat) {
# get all the trajectory variables, with and without descendants
trajectory_children <- xml_name(xml_children(xml_find_first(xml_dat, "//trajectory")))
# get only those variables without descendants. hnc: have no children
traj_hnc_names <- names(have_no_children(xml_dat, "trajectory"))
traj_hnc_idx <- which(trajectory_children %in% traj_hnc_names)
traj_hnc <- xml_text(xml_children(xml_find_first(xml_dat, "//trajectory")))[traj_hnc_idx]
names(traj_hnc) <- traj_hnc_names
# dataframe and datatable
data.frame(t(traj_hnc), stringsAsFactors = FALSE)
}
t_attr <- get_trajectory_attributes_df(dat_9f7)
t_meta <- get_trajectory_metadata(dat_9f7)
trajectory_dt <- data.table(cbind(t_attr, t_meta))
trajectory_dt
#> uidWell uidWellbore
#> 1: 5da3aeeb-12c9-4732-a059-e3a8d7c32442 eba2d47b-95f4-468f-856c-32c72d706a96
#> uid nameWell nameWellbore name objectGrowing
#> 1: 5VFNI35 NO 15/9-F-7 NO 15/9-F-7 MWD-15/9-F-7 false
#> dTimTrajStart dTimTrajEnd mdMn mdMx magDeclUsed
#> 1: 2016-07-28T08:33:43.000Z 2016-07-28T09:26:52.000Z 0 1083 0
#> gridCorUsed aziVertSect dispNsVertSectOrig dispEwVertSectOrig aziRef
#> 1: 0 0 0 0 true northtrajectoryStation dataframe for the 2nd well
# uid dataframe
get_trajectoryStation_uid_df <- function(xml_dat) {
# get values for uid attribute of trajectoryStation
# these are the well ids
tS.uid <- xml_dat %>%
xml_find_all("//trajectoryStation") %>%
xml_attr("uid")
as_tibble(data.frame(uid = tS.uid, stringsAsFactors = FALSE))
}
# measurements dataframe
get_trajectoryStation_meas_df <- function(xml_dat) {
num_trajectoryStation <- get_numrows_parent_node(xml_dat, "trajectoryStation",
attribute = "uid")
tS.trajectoryStation_df <- nodes_as_df(xml_dat, "trajectoryStation",
num_trajectoryStation)
as_tibble(tS.trajectoryStation_df)
}
# commonData
get_trajectoryStation_cData_df <- function(xml_dat, nrows) {
tS.cD_df <- nodes_as_df(xml_dat, node = "trajectoryStation/commonData", max_obs = nrows)
as_tibble(tS.cD_df)
}
# corUsed
get_trajectoryStation_cUsed_df <- function(xml_dat, nrows) {
tS.cU_df <- nodes_as_df(xml_dat, node = "trajectoryStation/corUsed", max_obs = nrows)
as_tibble(tS.cU_df)
}
# number of rows
num_tS <- get_numrows_parent_node(dat_9f7, "trajectoryStation", attribute = "uid")
# build complete dataframe for trajectoryStation
tS.uid_df <- get_trajectoryStation_uid_df(dat_9f7)
tS.measurements_df <- get_trajectoryStation_meas_df(dat_9f7)
tS.corUsed <- get_trajectoryStation_cUsed_df(dat_9f7, num_tS)
tS.commonData_df <- get_trajectoryStation_cData_df(dat_9f7, num_tS)
trajectoryStation_df <- as_tibble(cbind(tS.uid_df,
tS.measurements_df,
tS.corUsed,
tS.commonData_df)
)
make_id_to_trajectoryStation_dt <- function(tS_df) {
# create a new column id for relationship to another table
id <- tS_df[1, "uid"]
sub_id <- gsub(pattern = "_.*$", replacement = "", x = id)
sub_id
tS_df <- tS_df %>%
mutate(id = sub_id) %>%
select(id, everything()) %>%
as_tibble()
data.table(tS_df)
}
trajectoryStation_dt <- make_id_to_trajectoryStation_dt(trajectoryStation_df)
# as_tibble(trajectoryStation_dt)
# inner join
make_trajectory_table <- function(t_dt, tS_dt) {
setkey(t_dt, "uid")
setkey(tS_dt, "id")
# inner join
result <- t_dt[tS_dt, nomatch=0]
result %>%
as_tibble()
}
t_9f7_dt <- make_trajectory_table(trajectory_dt, trajectoryStation_dt)
well_9f7_df <- t_9f7_dt
t_9f7_dt
#> # A tibble: 42 × 43
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 2 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 3 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 4 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 5 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 6 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 7 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 8 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 9 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 10 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> # … with 32 more rows, and 36 more variables: dTimTrajStart <chr>,
#> # dTimTrajEnd <chr>, mdMn <chr>, mdMx <chr>, magDeclUsed <chr>,
#> # gridCorUsed <chr>, aziVertSect <chr>, dispNsVertSectOrig <chr>,
#> # dispEwVertSectOrig <chr>, aziRef <chr>, i.uid <chr>, dTimStn <chr>,
#> # typeTrajStation <chr>, md <chr>, tvd <chr>, incl <chr>, azi <chr>,
#> # dispNs <chr>, dispEw <chr>, vertSect <chr>, dls <chr>,
#> # typeSurveyTool <chr>, rateTurn <chr>, rateBuild <chr>, …Test the well dataframe structures
We test if both wells have identical variables otherwise we couldn’t be able to combine them. This is also a test that our functions are working well so far, at least for these two wells. Adding more wells could present a challenge if the new well has stored a different number of variables, so, the functions will have to check for all possible cases.
# compare the two wells
identical(names(t_9f9_dt), names(t_9f7_dt))
#> [1] TRUEMaking it reproducible
Now, we can put all these functions in an R script, and everything should work much faster. In this example, we are converting the WITSML to dataframes for well Norway-Statoil-NO 15_$47$_9-F-7. We will call it by the last identifier 9f7 from now on. You will see that this well has more trajectory stations; 43 to be exact. Many more than the first well 9f9 that corresponds to well Norway-Statoil-NO 15_$47$_9-F-9.
source("witsml-trajectory.R")
all_files_xml <- list.files("./witsml", recursive = TRUE, full.names = TRUE,
include.dirs = TRUE, pattern = "*.xml")
# Select the trajectory file
# get the file for trajectory
traj_files <- grep(pattern = "trajectory", ignore.case = TRUE,
value = TRUE, x = all_files_xml)
well_9f7 <- traj_files[2]
well_9f7_df <- convert_witsml_to_df(well_9f7)
well_9f7_df
#> # A tibble: 42 × 43
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 2 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 3 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 4 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 5 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 6 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 7 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 8 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 9 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 10 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> # … with 32 more rows, and 36 more variables: dTimTrajStart <chr>,
#> # dTimTrajEnd <chr>, mdMn <chr>, mdMx <chr>, magDeclUsed <chr>,
#> # gridCorUsed <chr>, aziVertSect <chr>, dispNsVertSectOrig <chr>,
#> # dispEwVertSectOrig <chr>, aziRef <chr>, i.uid <chr>, dTimStn <chr>,
#> # typeTrajStation <chr>, md <chr>, tvd <chr>, incl <chr>, azi <chr>,
#> # dispNs <chr>, dispEw <chr>, vertSect <chr>, dls <chr>,
#> # typeSurveyTool <chr>, rateTurn <chr>, rateBuild <chr>, …Combine the observations of the two wells with rbind
Now it’s the time to combine the measurements of both wells. We use the rbind() function which glue them by rows. Now, we should have 67 rows.
# bind two wells and create a common dataframe
all_wells <- rbind(well_9f7_df, well_9f9_df)
all_wells
#> # A tibble: 67 × 43
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 2 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 3 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 4 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 5 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 6 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 7 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 8 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 9 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> 10 5da3aeeb-12… eba2d47b-95f4-… 5VFN… NO 15/9… NO 15/9-F-7 MWD-1… false
#> # … with 57 more rows, and 36 more variables: dTimTrajStart <chr>,
#> # dTimTrajEnd <chr>, mdMn <chr>, mdMx <chr>, magDeclUsed <chr>,
#> # gridCorUsed <chr>, aziVertSect <chr>, dispNsVertSectOrig <chr>,
#> # dispEwVertSectOrig <chr>, aziRef <chr>, i.uid <chr>, dTimStn <chr>,
#> # typeTrajStation <chr>, md <chr>, tvd <chr>, incl <chr>, azi <chr>,
#> # dispNs <chr>, dispEw <chr>, vertSect <chr>, dls <chr>,
#> # typeSurveyTool <chr>, rateTurn <chr>, rateBuild <chr>, …Simplify the data structure by nesting the two wells
With the two wells put together we should be almost ready. But we don’t want to show all the measurements; we want just to focus on the wells. So far, we have two wells with 67 rows but what about later when we have ten or a hundred. Then, it would consume lot of memory and screen to see through all those records.
What we want is to show only the wells and start performing operations directly on them. We do this by using the tidyr function nest().
# nest the two well so they show as one row each
wells_nested <-
all_wells %>%
nest(-uid) %>%
print()
#> # A tibble: 2 × 2
#> uid data
#> <chr> <list>
#> 1 5VFNI35 <tibble [42 × 42]>
#> 2 4VIRG33 <tibble [25 × 42]>Add new wells
We will add one more well: Norway-Statoil-NO 15_$47$_9-F-4. This well has 87 measurement points for its trajectory, which is the same as saying that the well has 87 trajectoryStation items.
This time we use only one function convert_witsml_to_df(), one that resides in the script witsml-trajectory.R. This function performs all the data extraction and conversion that we saw at the beginning.
# convert a WITSML trajectory to dataframe
well_9f4 <- traj_files[1]
well_9f4_df <- convert_witsml_to_df(well_9f4)
well_9f4_df
#> # A tibble: 87 × 43
#> uidWell uidWellbore uid nameWell nameWellbore name objectGrowing
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 2 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 3 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 4 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 5 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 6 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 7 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 8 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 9 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> 10 5e023a7f-1b… dbffce7a-74d8-… 5VIR… NO 15/9… NO 15/9-F-4 MWD-1… false
#> # … with 77 more rows, and 36 more variables: dTimTrajStart <chr>,
#> # dTimTrajEnd <chr>, mdMn <chr>, mdMx <chr>, magDeclUsed <chr>,
#> # gridCorUsed <chr>, aziVertSect <chr>, dispNsVertSectOrig <chr>,
#> # dispEwVertSectOrig <chr>, aziRef <chr>, i.uid <chr>, dTimStn <chr>,
#> # typeTrajStation <chr>, md <chr>, tvd <chr>, incl <chr>, azi <chr>,
#> # dispNs <chr>, dispEw <chr>, vertSect <chr>, dls <chr>,
#> # typeSurveyTool <chr>, rateTurn <chr>, rateBuild <chr>, …Nest the new well
So, we have 87 trajectory measurements for the well. Again, we don’t want to see all of them but just the well. So, we nest the structure. What we will see from now on is one row representing the well with its uid.
Later, if you need to undo the nesting operation, you just use the function unnest().
# nesting the new well
nested_9f4 <-
well_9f4_df %>%
nest(-uid) %>%
print()
#> # A tibble: 1 × 2
#> uid data
#> <chr> <list>
#> 1 5VIRG33 <tibble [87 × 42]>The new well should be able now to join the other two wells nested structure. It should be a straight operation with the function rbind(). Since all of them are just one row, at the end of the binding we should have now three rows. The trajectory measurements are living as a list component in the column data.
# bind the existing wells with the new one
wells_nested_3 <- rbind(wells_nested, nested_9f4)
wells_nested_3
#> # A tibble: 3 × 2
#> uid data
#> <chr> <list>
#> 1 5VFNI35 <tibble [42 × 42]>
#> 2 4VIRG33 <tibble [25 × 42]>
#> 3 5VIRG33 <tibble [87 × 42]>Transforming the drilling data
The next step is performing some operations with the data in the nested structures. First, we want to do the type conversion of few of the variables. We should convert the character types to the double type for the variables:
md
tvd
incl
azi
rateTurn
rateBuildAfter they are converted to numeric variables, we will be able to plot them and start making discoveries.
wells_kvars <-
wells_nested_3 %>% # this is the nested structure
unnest(data) %>% # unnest and select the variables
select(nameWell, md, tvd, incl, azi, rateTurn, rateBuild) %>%
mutate(md = as.double(md), tvd = as.double(tvd), # convert to double
incl = as.double(incl), azi = as.double(azi),
rateTurn = as.double(rateTurn), rateBuild = as.double(rateBuild)) %>%
print()
#> # A tibble: 154 × 7
#> nameWell md tvd incl azi rateTurn rateBuild
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 NO 15/9-F-7 0 0 0 0 NA NA
#> 2 NO 15/9-F-7 146. 146. 0 0 0 0
#> 3 NO 15/9-F-7 160 160. 0.00401 4.79 -0.106 0.000285
#> 4 NO 15/9-F-7 170 170. 0.00454 4.76 -0.00284 0.0000524
#> 5 NO 15/9-F-7 180 180. 0.00524 4.58 -0.0186 0.0000698
#> 6 NO 15/9-F-7 190 190. 0.00384 4.67 0.00965 -0.000140
#> 7 NO 15/9-F-7 199 199. 0.00559 4.54 -0.0142 0.000194
#> 8 NO 15/9-F-7 208 208. 0.00541 3.96 -0.0651 -0.0000194
#> 9 NO 15/9-F-7 218 218. 0.00698 4.27 0.0314 0.000157
#> 10 NO 15/9-F-7 229 229. 0.00436 4.36 0.00820 -0.000238
#> # … with 144 more rowsPlotting drilling data
With the variables now converted to double, we start plotting them. The first plot will be MD vs TVD to find out how deviated is the well.
# MD vs TVD for three wells
library(ggplot2)
ggplot(wells_kvars, aes(x = md, y = tvd, color = nameWell)) +
geom_line(size=1) +
labs(title = "MD vs TVD for three wells")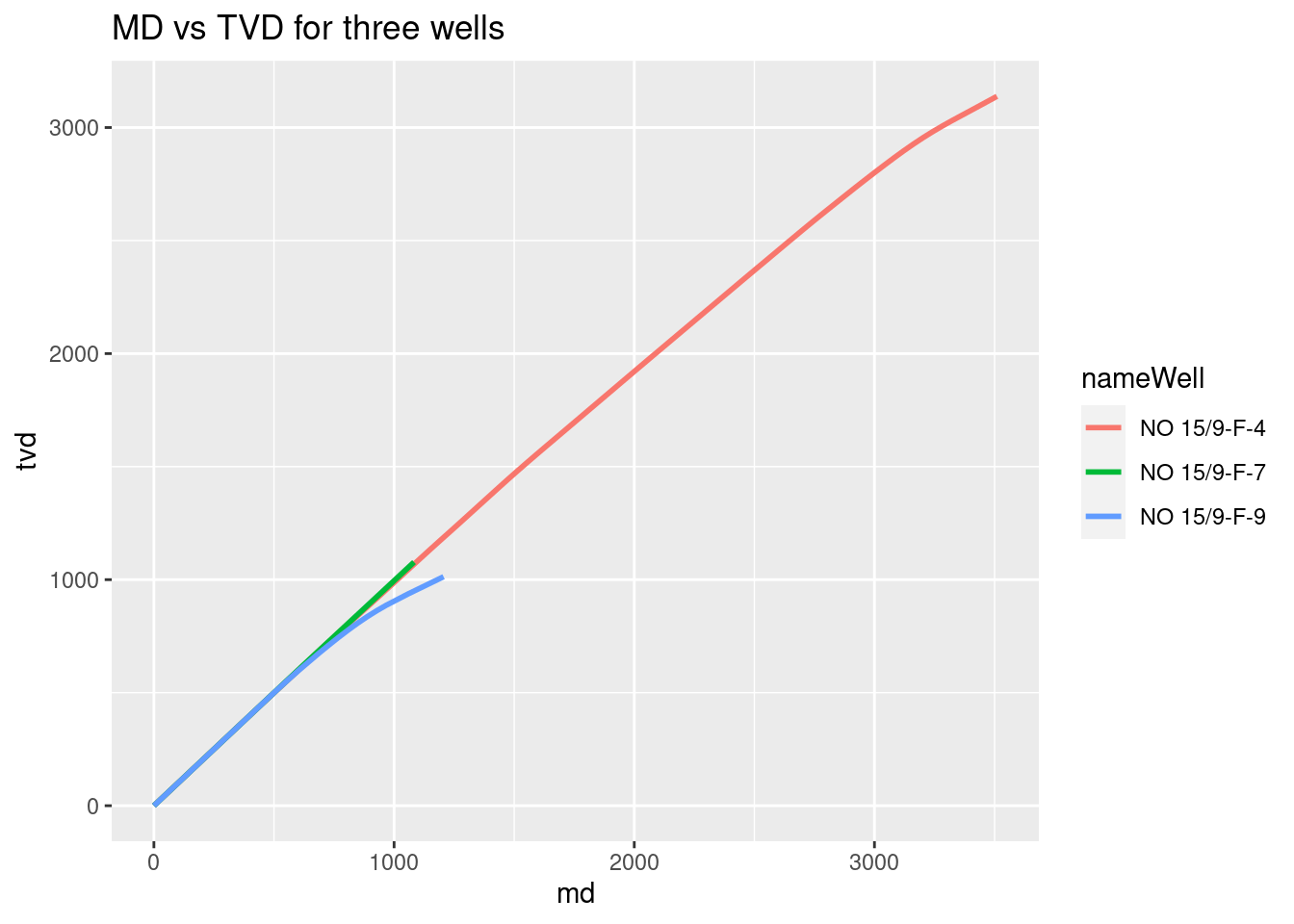
Facet plot of MD vs TVD
Here is another way of visualizing the plot above. We use facets to get rid of that overlapping in the former plot.
# plot facets of the three wells
# MD vs TVD for three wells
ggplot(wells_kvars, aes(x = md, y = tvd, color = nameWell)) +
geom_line(size=1) +
facet_grid(. ~ nameWell) +
labs(title = "MD vs TVD for three wells")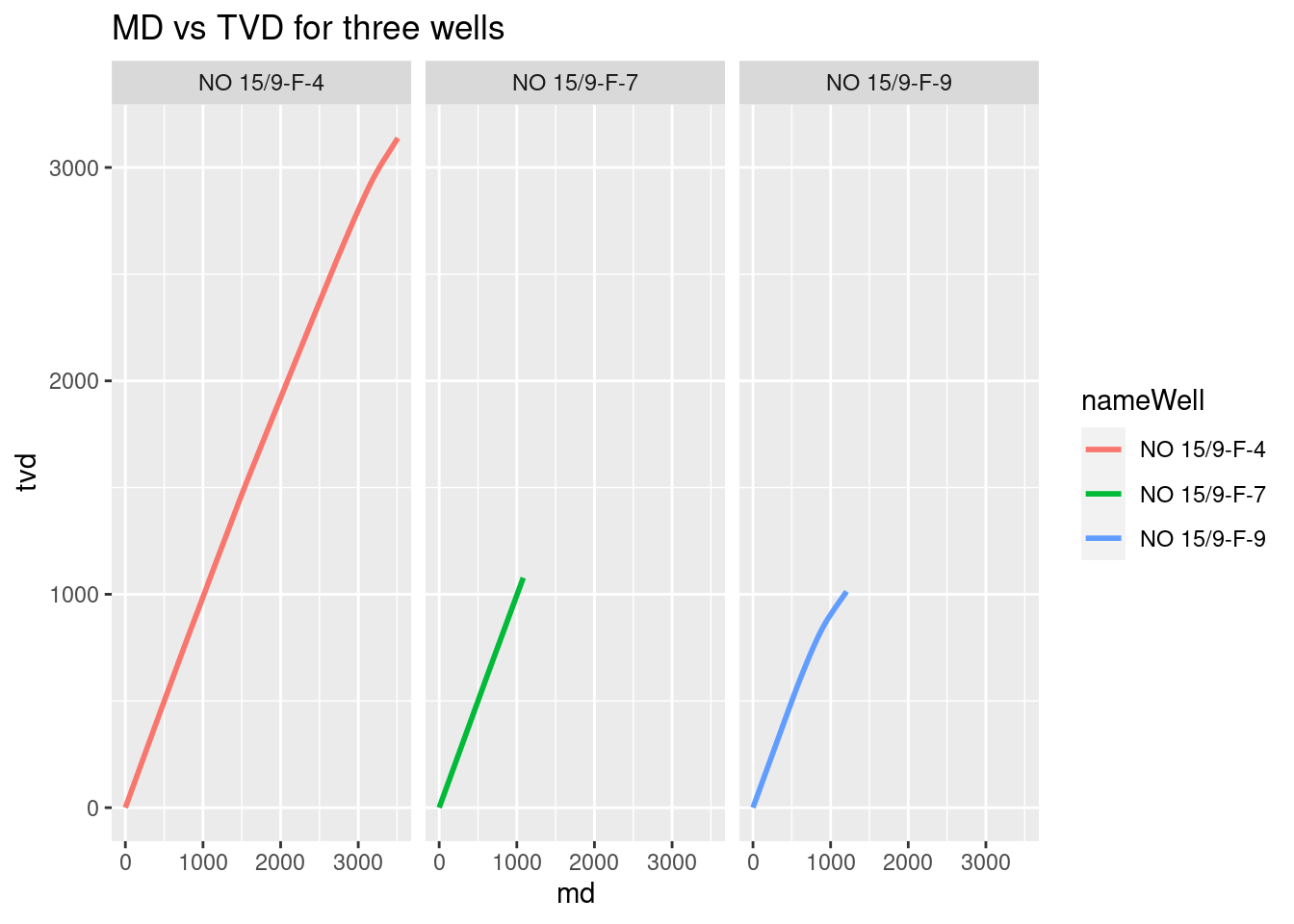
Next, it is the turn of inclination vs azimut.
# Inclination vs Azimuth for three wells
ggplot(wells_kvars, aes(x = incl, y = azi, color = nameWell)) +
geom_line(size=1) +
facet_grid(. ~ nameWell) +
labs(title = "Inclination vs Azimuth for three wells")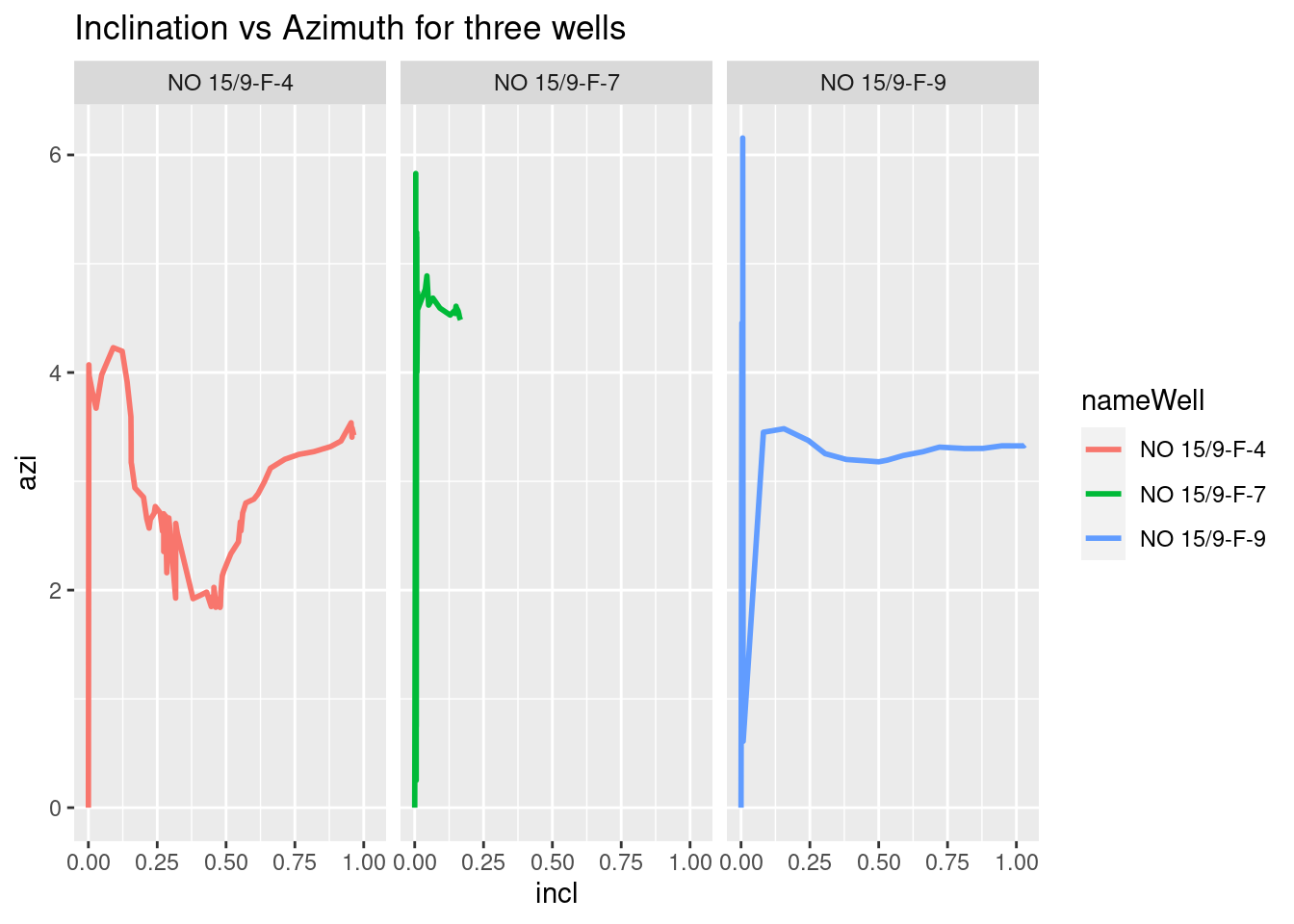
We notice that the x-axis remains the same for al of the plots. We can set it free to let the x axis expand and follow the data. Just be careful in reading the data in the x-axis; they are not fixed anymore.
# # rateTurn in radians per meter
ggplot(wells_kvars, aes(x = tvd, y = rateTurn, color = nameWell)) +
geom_line(size=1) +
facet_grid(. ~ nameWell, scales="free_x") +
labs(title = "TVD vs Rate of Turn for three wells")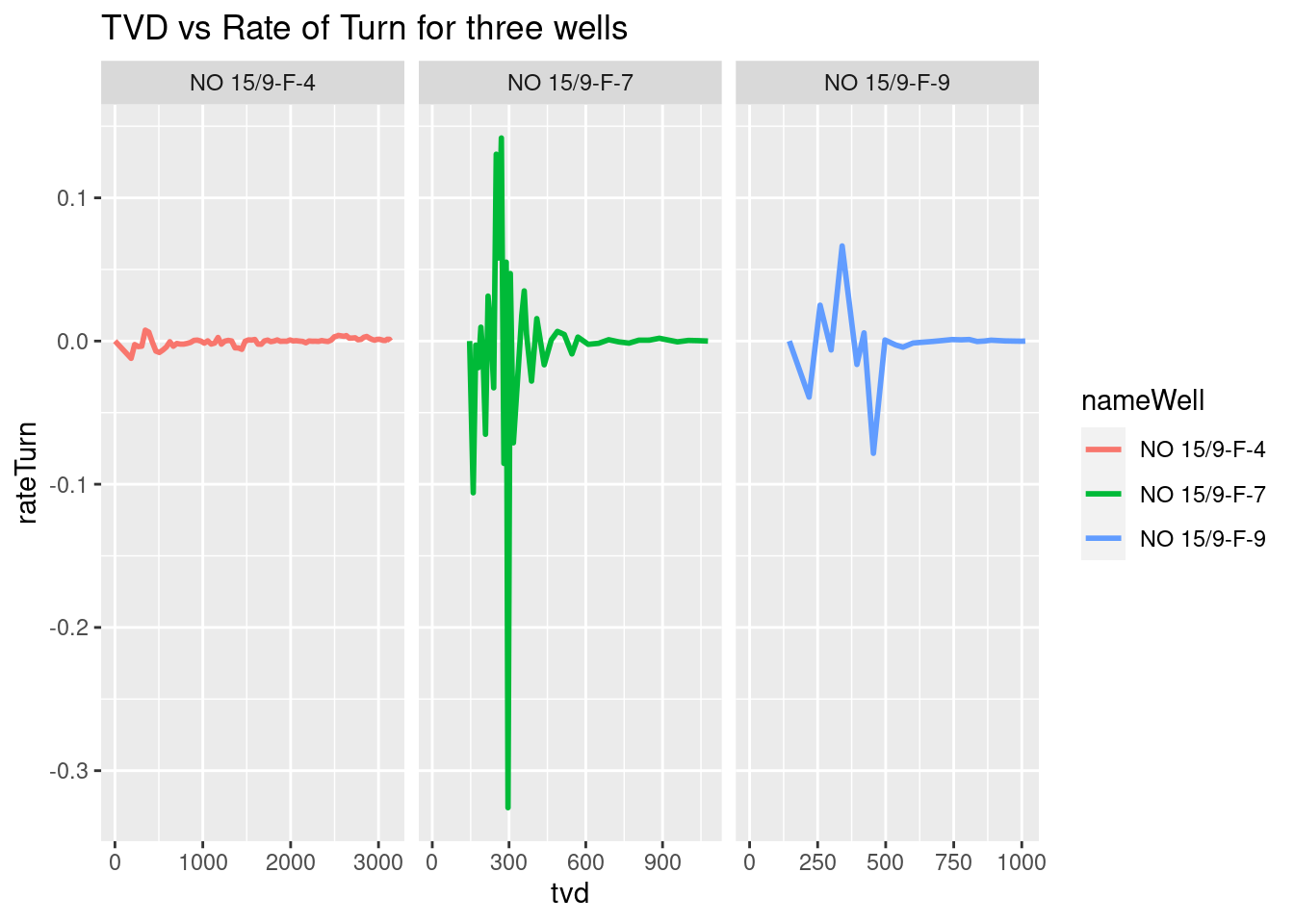
We do the same with the plot TVD vs Rate of Build.
# rateBuild in radians per meter
ggplot(wells_kvars, aes(x = tvd, y = rateBuild, color = nameWell)) +
geom_line(size=1) +
facet_grid(. ~ nameWell, scales = "free_x") +
labs(title = "TVD vs Rate of Build for three wells")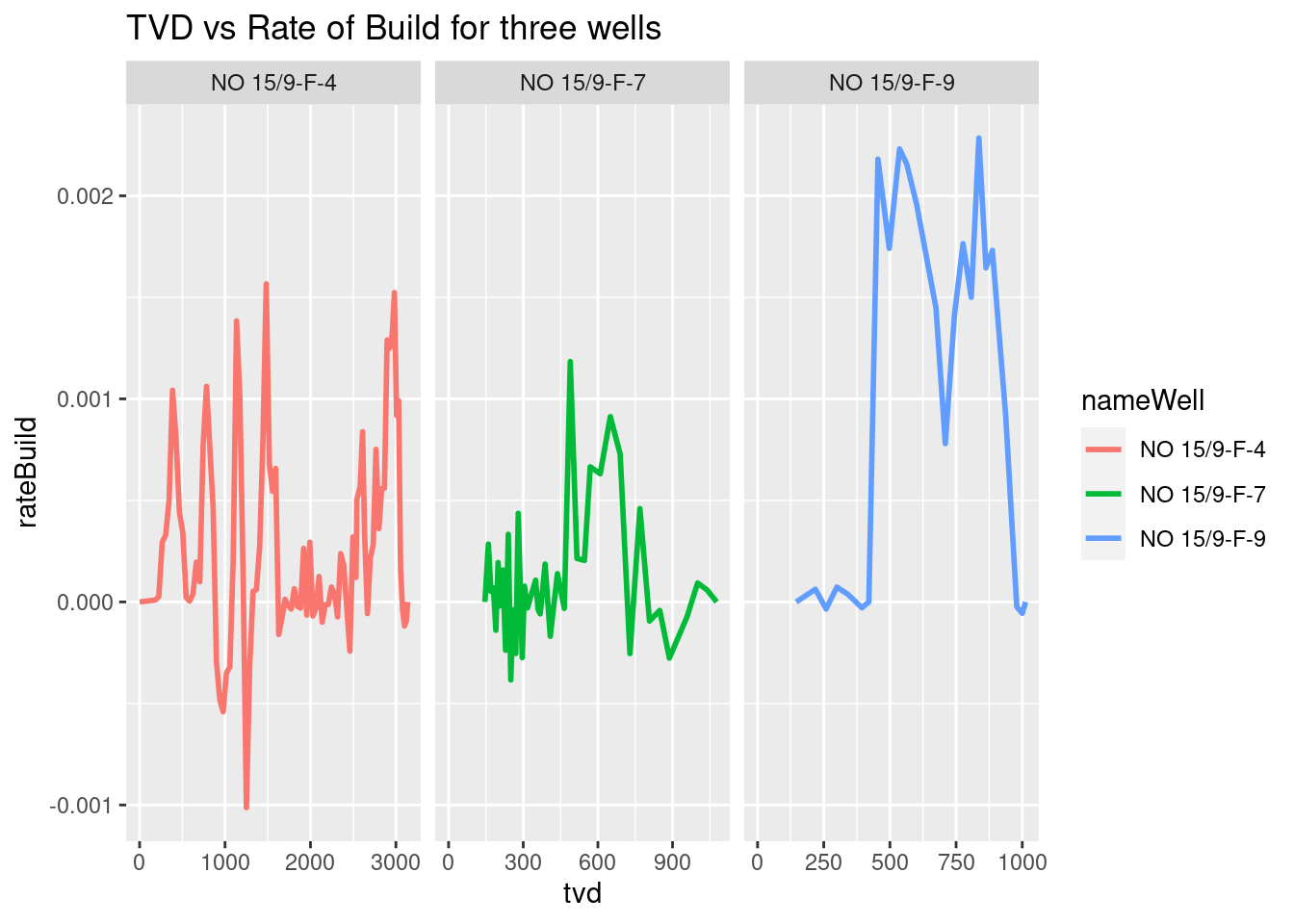
Notes
For the first row of
trajectoryStation, which corresponds to theTIE_POINT, fill all the empty variables (those absent) withNA. Thedata.tablefunction works very well compensating those variables that are incomplete but filling them with default values, which is not good. We see, for instance, that for first member of thetrajectoryStation, the variables present are only 10. Normally, they should be 20, if we countcommonDataandcorUsed, which are the only two which have children nodes.In upcoming versions, we should take care of coercing the variables to their corresponding types. By default, in this example, we’ve got all the variables as character. Since we know in advance the data types because of the WITSML standard, we could use the R package
readrto do the coercion.As we get familiar with the WITSML hierarchies, we could start using loops or
applyfunctions to convert the tree structures to dataframes.Functions can be implemented later to get the number of trajectory stations, find which
trajectoryStationdoes not have its complete set of variables, or extract a particular trajectory measurement.In this long example, we used only one well for the details. That’s why we obtained only one trajectory file. Other wells could have more than one trajectory file. Later we could implement a function that scans all the folders and generates a summary statistic of the number of folders, number of files per well, size, etc. Update. We added lately two more wells.
The specification for the
trajectoryandtrajectoryStationobjects can be found in the Energistics website. Refer to WITSML 1.3.1.1. Each one of the objects, nodes and subnodes are explained in detail.
References
WITSML 1.3.1.1: http://w3.energistics.org/schema/witsml_v1.3.1.1_data/doc/WITSML_Schema_docu.htm
WITSML 1.4.0 schema: http://w3.energistics.org/schema/witsml_v1.4.0_data/doc/witsml_schema_overview.html