Introduction
If you you love searching, finding, reading and collecting papers when working on a particular petroleum engineering topic, keep reading. We will be using some digital tools and stats to keep up with the 21 century. :)
I have just published a new R package called petro.One which website you could see here. All the code, notebooks, datasets, figures, etc., are located in GitHub at this repository. Everything is explained in detail there but I will show here a summary of what the package does.
Motivation
The standard way of searching for papers in OnePetro is using a web browser to enter the search terms for a particular paper we are looking for.
# insert pictureThe result will come in web pages with which would contain dozens, hundreds or thousand of paper titles. We will need to browse all the resulting pages to find papers that have a better match with the subject we are researching. By using some statistical tools available through R, the search could turn in highly profitable in terms of time, matching quality and selection of the papers.
The search keywords are entered through the R console and the papers will return in the form of a dataframe, which is identical to a spreadsheet: rows of paper titles and columns with details from the metadata extracted from the web page. With the dataframe already in our computers we could perform a thorough analysis and narrow down to the most ideal papers.
What is behind the paper search
A typical OnePetro search URL would look like this:
# codewhich could be explained with the descriptions in this figure:
# pictureThis is not difficult to figure it out if you send some query searches in OnePetro and see the URL in the browser. The parameters shown above are not all but some of the most important.
Type of Documents
Another finding is the type of documents or papers. They are few. The package petro.One has a function that let you obtain the number of paper per document type. So far, what I have found is that more abundant papers are in the categories of “conference” and “journal” papers. Below is a list of all the type of papers available through OnePetro:
# insert textThe data mining process
Above we briefly explained a couple of the text retrieval steps. The details can be found in the petro.One package website. After we obtained the paper titles -could be a dozen, a hundred or thousands-, we get into the data mining process. There are several R packages for doing this. You could this data mining in a different way as well.
Keep in mind that what we have retrieved are only the titles of the papers that match the keyword that we entered. But which of the several hundreds of papers is the best candidate for downloading and start reading? That is the key question. We need to reduce the number of papers returned to just a handful. How? By performing some classification, ranking and sorting of the terms contained in the titles.
A paper title contains several terms or words. Terms is what is used in data science. Let’s say that one of the papers returned has as a title this:
# textWhat are the terms that carry information that is key for our selection? One is “reservoir”, the next “characterization”, the next could be “feedforward”, and the last “neural” and “network”.
Here is a decision we need to make: (1) are we interested in “reservoir”, or “reservoir characterization”?; (2) is “feedforward” a sensitive term in our reading list; (3) is the word “using” contributing value to the paper selection?; (4) which one of these terms: “neural”, “neural network”, or “neural networks”, or “network”, would bring us the best papers in our search?
The questions above cover part of the most important concerns.
We haven’t talked about if the word have to be in uppercase or lowercase, if “feedforward” is correct they way is being spelled out. Or is it “feed-forward”? We haven’t yet discussed if punctuation symbols would bring extra value to the search. And the same with terms that have a common root like fracture, fracturing, frack, fracking, fractures, etc. These words should have to be compressed to a common ancestor. This last step is called stemming.
What I have just described are few of the steps that our brains perform naturally to arrive to a selection of a handful of papers. The difference is that machines today can do that faster, better and in a bigger volume of papers.
Viewing the results
In short, after you enter your search you should obtain plots like these:
# wordcloudAnd also a term bar plot for terms that contain one word:
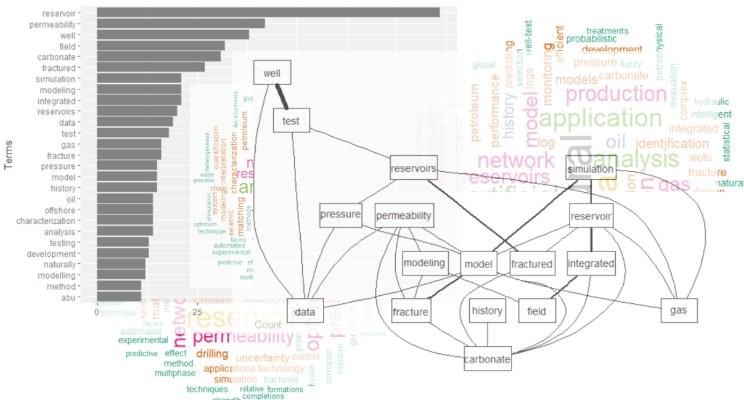
# plotOr another plot showing the relationships between the terms in all the papers that return from your search. Note the thickness of the connecting lines; it means stronger relationship:
# plotThe purpose of all of this is to detect rapidly and narrow down the list of papers to retrieve and start perusing the documents.
Another use that you can give to this R package is saving your collection of papers in a dataset (in a database), that you could use later when the opportunity calls again.
You can even start classifying your papers metadata by discipline: what papers belong to completion, production, reservoir, sand control, artificial lift, petrophysics, PVT, geology, geomechanics, etc. This is what we call classification. If you have a trained agent, with some deep learning algorithm, then this classification could be done in the background without your intervention.
Doing the paper search is now more efficient and more productive. And it gets improving with a new search as new papers start adding to your dataset.
Please, feel free to fork the package petro.One in GitHub and play with it. Of course, all collaboration is welcome.
Follow me in Tweeter at https://twitter.com/OilGains.